
源码来自https://github.com/jadore801120/attention-is-all-you-need-pytorch
缩放点积
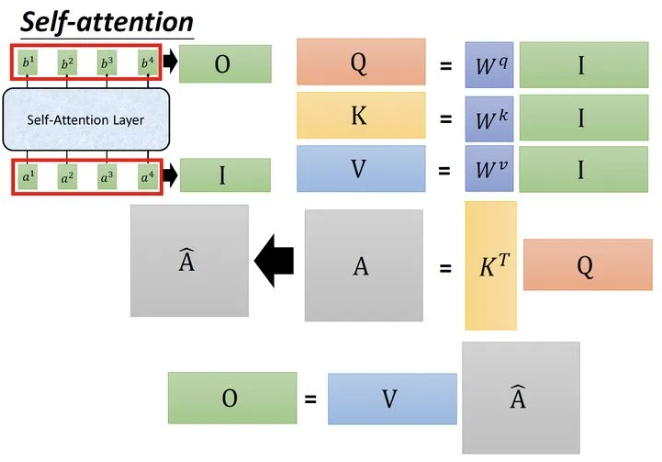
class ScaledDotProductAttention(nn.Module):
""" 缩放点积注意力 """
def __init__(self, temperature, attn_dropout=0.1):
super().__init__()
self.temperature = temperature # 缩放点积的温度参数
self.dropout = nn.Dropout(attn_dropout) # 注意力权重的Dropout层
def forward(self, q, k, v, mask=None):
# 计算查询和键的点积,并除以温度参数进行缩放
attn = torch.matmul(q / self.temperature, k.transpose(2, 3))
if mask is not None:
# 将掩码应用于注意力分数,将掩码位置设置为一个非常小的值
attn = attn.masked_fill(mask == 0, -1e9)
# 对注意力分数应用softmax获取注意力权重,然后应用Dropout
attn = self.dropout(F.softmax(attn, dim=-1))
# 通过将注意力权重与值相乘计算最终输出
output = torch.matmul(attn, v)
return output, attn # 返回输出和注意力权重位置编码
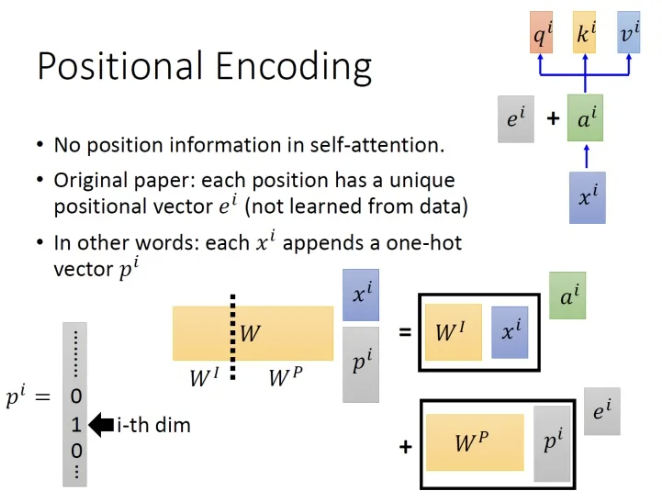
lass PositionalEncoding(nn.Module):
""" 位置编码模块 """
def __init__(self, d_hid, n_position=200):
# 初始化位置编码类,定义其参数
super(PositionalEncoding, self).__init__()
self.register_buffer('pos_table', self._get_sinusoid_encoding_table(n_position, d_hid))
def _get_sinusoid_encoding_table(self, n_position, d_hid):
""" 正弦位置编码表 """
def get_position_angle_vec(position):
# 获取位置角度向量
return [position / np.power(10000, 2 * (hid_j // 2) / d_hid) for hid_j in range(d_hid)]
# 生成正弦编码表
sinusoid_table = np.array([get_position_angle_vec(pos_i) for pos_i in range(n_position)])
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # 维度 2i
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # 维度 2i+1
return torch.FloatTensor(sinusoid_table).unsqueeze(0) # (1, N, d)
def forward(self, x):
# 前向传播函数,定义输入和输出
# x (B, N, d)
return x + self.pos_table[:, :x.size(1)].clone().detach()多头注意力
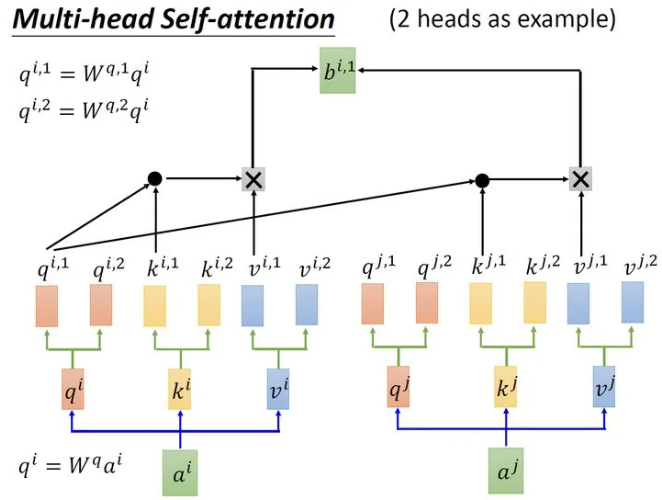
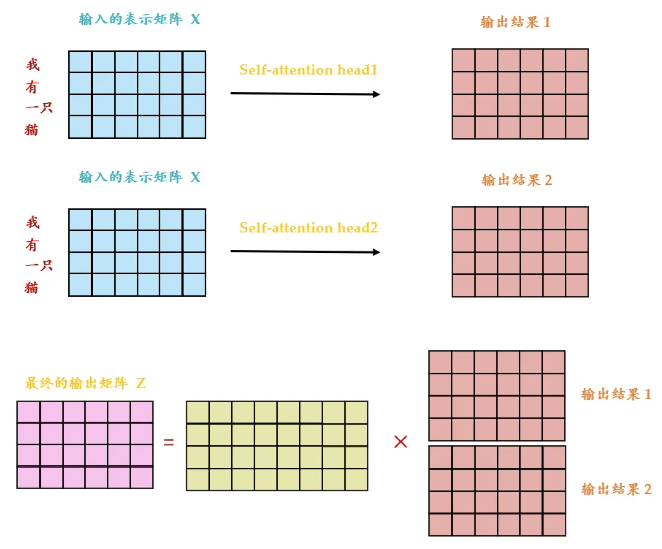
class MultiHeadAttention(nn.Module):
""" 多头注意力模块 """
def __init__(self, n_head, d_model, d_k, d_v, dropout=0.1):
super().__init__()
self.n_head = n_head # 多头注意力的头数
self.d_k = d_k # 每个头的键的维度
self.d_v = d_v # 每个头的值的维度
# 定义线性变换层,用于生成查询、键和值
self.w_qs = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_ks = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_vs = nn.Linear(d_model, n_head * d_v, bias=False)
self.fc = nn.Linear(n_head * d_v, d_model, bias=False) # 最后的线性变换层
# 定义缩放点积注意力机制
self.attention = ScaledDotProductAttention(temperature=d_k ** 0.5)
self.dropout = nn.Dropout(dropout) # Dropout层
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6) # LayerNorm层
def forward(self, q, k, v, mask=None):
d_k, d_v, n_head = self.d_k, self.d_v, self.n_head
sz_b, len_q, len_k, len_v = q.size(0), q.size(1), k.size(1), v.size(1)
residual = q # 残差连接
# 通过预注意力投影:b x lq x (n*dv)
# 分离不同的头:b x lq x n x dv
q = self.w_qs(q).view(sz_b, len_q, n_head, d_k)
k = self.w_ks(k).view(sz_b, len_k, n_head, d_k)
v = self.w_vs(v).view(sz_b, len_v, n_head, d_v)
# 转置以进行注意力点积:b x n x lq x dv
q, k, v = q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2)
if mask is not None:
mask = mask.unsqueeze(1) # 为头轴广播掩码
q, attn = self.attention(q, k, v, mask=mask) # 计算注意力
# 转置以将头维度移回:b x lq x n x dv
# 组合最后两个维度以连接所有头:b x lq x (n*dv)
q = q.transpose(1, 2).contiguous().view(sz_b, len_q, -1)
q = self.dropout(self.fc(q)) # 应用Dropout和最后的线性变换
q += residual # 加上残差连接
q = self.layer_norm(q) # 应用LayerNorm
return q, attn # 返回输出和注意力权重前馈神经网络
class PositionwiseFeedForward(nn.Module):
""" 前馈神经网络模块 """
def __init__(self, d_in, d_hid, dropout=0.1):
super().__init__()
self.w_1 = nn.Linear(d_in, d_hid) # 第一层线性变换
self.w_2 = nn.Linear(d_hid, d_in) # 第二层线性变换
self.layer_norm = nn.LayerNorm(d_in, eps=1e-6) # 层归一化
self.dropout = nn.Dropout(dropout) # Dropout层
def forward(self, x):
residual = x # 残差连接
x = self.w_2(F.relu(self.w_1(x))) # 通过第一层线性变换后应用ReLU激活函数,再通过第二层线性变换
x = self.dropout(x) # 应用Dropout
x += residual # 加上残差连接
x = self.layer_norm(x) # 应用层归一化
return x # 返回输出编码器层
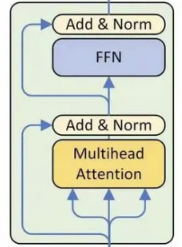
class EncoderLayer(nn.Module):
""" 编码器层 """
def __init__(self, d_model, d_inner, n_head, d_k, d_v, dropout=0.1):
super(EncoderLayer, self).__init__()
# 多头注意力机制层
self.slf_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
# 前馈神经网络层
self.pos_ffn = PositionwiseFeedForward(d_model, d_inner, dropout=dropout)
def forward(self, enc_input, slf_attn_mask=None):
# 通过多头注意力机制层
enc_output, enc_slf_attn = self.slf_attn(
enc_input, enc_input, enc_input, mask=slf_attn_mask)
# 通过前馈神经网络层
enc_output = self.pos_ffn(enc_output)
# 返回编码器输出和自注意力权重
return enc_output, enc_slf_attn解码器层
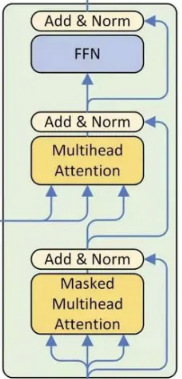
class DecoderLayer(nn.Module):
""" 解码器层 """
def __init__(self, d_model, d_inner, n_head, d_k, d_v, dropout=0.1):
super(DecoderLayer, self).__init__()
# 定义自注意力机制层
self.slf_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
# 定义编码器-解码器注意力机制层
self.enc_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
# 定义前馈神经网络层
self.pos_ffn = PositionwiseFeedForward(d_model, d_inner, dropout=dropout)
def forward(
self, dec_input, enc_output,
slf_attn_mask=None, dec_enc_attn_mask=None):
# 通过自注意力机制层
dec_output, dec_slf_attn = self.slf_attn(
dec_input, dec_input, dec_input, mask=slf_attn_mask)
# 通过编码器-解码器注意力机制层
dec_output, dec_enc_attn = self.enc_attn(
dec_output, enc_output, enc_output, mask=dec_enc_attn_mask)
# 通过前馈神经网络层
dec_output = self.pos_ffn(dec_output)
# 返回解码器输出、自注意力权重和编码器-解码器注意力权重
return dec_output, dec_slf_attn, dec_enc_attn编码器
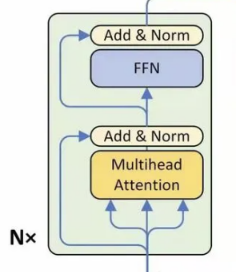
class Encoder(nn.Module):
""" 编码器模型"""
def __init__(
self, n_src_vocab, d_word_vec, n_layers, n_head, d_k, d_v,
d_model, d_inner, pad_idx, dropout=0.1, n_position=200):
"""
n_src_vocab: 源词汇表的大小。
d_word_vec: 词向量的维度。
n_layers: 编码器层的数量。
n_head: 注意力头的数量。
d_k: 键的维度。
d_v: 值的维度。
d_model: 模型的维度。
d_inner: 内部前馈层的维度。
pad_idx: 源序列的填充索引。
dropout: Dropout率(默认值为0
.1)。
n_position: 位置编码的数量(默认值为200)。
"""
# 初始化编码器类,定义其参数
super().__init__()
# 定义源词嵌入层
self.src_word_emb = nn.Embedding(n_src_vocab, d_word_vec, padding_idx=pad_idx)
# 定义位置编码层
self.position_enc = PositionalEncoding(d_word_vec, n_position=n_position)
# 定义Dropout层
self.dropout = nn.Dropout(p=dropout)
# 定义编码器层的堆栈
self.layer_stack = nn.ModuleList([
EncoderLayer(d_model, d_inner, n_head, d_k, d_v, dropout=dropout)
for _ in range(n_layers)])
# 定义层归一化层
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
def forward(self, src_seq, src_mask, return_attns=False):
# 前向传播函数,定义输入和输出
enc_slf_attn_list = [] # 用于存储自注意力权重的列表
# -- 前向传播
# 通过词嵌入层和位置编码层,并应用Dropout
enc_output = self.dropout(self.position_enc(self.src_word_emb(src_seq)))
# 应用层归一化
enc_output = self.layer_norm(enc_output)
# 通过每一层编码器层
for enc_layer in self.layer_stack:
enc_output, enc_slf_attn = enc_layer(enc_output, slf_attn_mask=src_mask)
# 如果需要返回注意力权重,则将其添加到列表中
enc_slf_attn_list += [enc_slf_attn] if return_attns else []
# 如果需要返回注意力权重,则返回输出和注意力权重列表
if return_attns:
return enc_output, enc_slf_attn_list
# 否则只返回输出
return enc_output,解码器
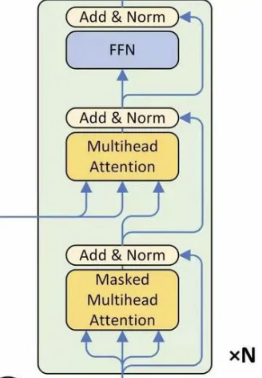
class Decoder(nn.Module):
""" 解码器模型 """
def forward(self, trg_seq, trg_mask, enc_output, src_mask, return_attns=False):
"""
前向传播函数
trg_seq: 目标序列
trg_mask: 目标序列的掩码
enc_output: 编码器的输出
src_mask: 源序列的掩码
return_attns: 是否返回注意力权重
"""
dec_slf_attn_list, dec_enc_attn_list = [], [] # 用于存储自注意力和编码器-解码器注意力权重的列表
# -- 前向传播
dec_output = self.dropout(self.position_enc(self.trg_word_emb(trg_seq))) # 通过词嵌入层和位置编码层,并应用Dropout
dec_output = self.layer_norm(dec_output) # 应用层归一化
for dec_layer in self.layer_stack:
dec_output, dec_slf_attn, dec_enc_attn = dec_layer(
dec_output, enc_output, slf_attn_mask=trg_mask, dec_enc_attn_mask=src_mask) # 通过每一层解码器层
dec_slf_attn_list += [dec_slf_attn] if return_attns else [] # 如果需要返回注意力权重,则将其添加到列表中
dec_enc_attn_list += [dec_enc_attn] if return_attns else [] # 如果需要返回注意力权重,则将其添加到列表中
if return_attns:
return dec_output, dec_slf_attn_list, dec_enc_attn_list # 返回解码器输出、自注意力权重和编码器-解码器注意力权重
return dec_output, # 否则只返回解码器输出掩码处理
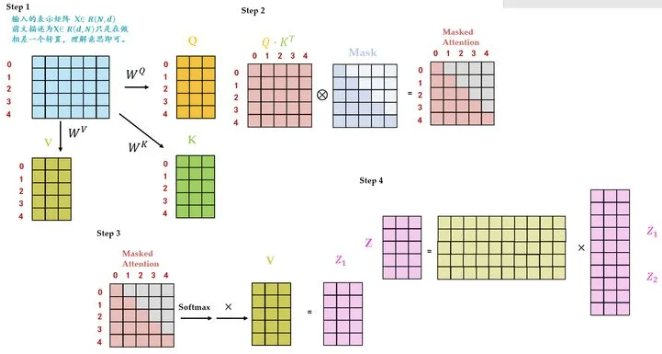
def get_pad_mask(seq, pad_idx):
# 获取填充掩码
# seq: 输入序列,形状为 (batch_size, seq_len)
# pad_idx: 填充值的索引
# 返回: 填充掩码,形状为 (batch_size, 1, seq_len)
return (seq != pad_idx).unsqueeze(-2)#用于生成填充掩码。返回的掩码可以用于在计算注意力分数时忽略填充部分。将掩码的形状扩展为 (batch_size, 1, seq_len),以便在后续的计算中进行广播
def get_subsequent_mask(seq):
""" 用于屏蔽后续信息的掩码 """
# 获取输入序列的批次大小和序列长度
sz_b, len_s = seq.size()
# 生成一个上三角矩阵,并将其对角线以上的元素设为0,其他元素设为1
#orch.ones((1, len_s, len_s), device=seq.device):生成一个形状为 (1, len_s, len_s) 的全为 1 的张量,device=seq.device 确保张量在与输入序列相同的设备上。
#torch.triu():获取上三角矩阵,返回一个新的张量,其中对角线以下的元素被置为0。
#1-torch.triu():将上三角矩阵中的元素取反,即对角线以下的元素为1,对角线以上的元素为0。
subsequent_mask = (1 - torch.triu(
torch.ones((1, len_s, len_s), device=seq.device), diagonal=1)).bool()
# 返回生成的掩码
return subsequent_maskTransformer
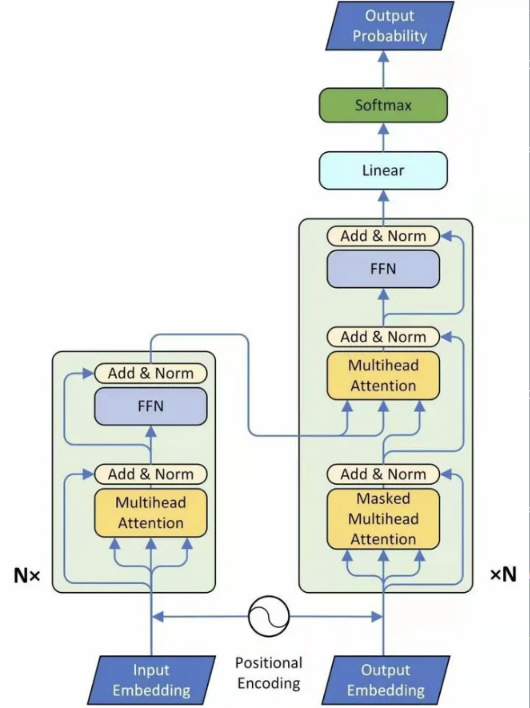
class Transformer(nn.Module):
""" Transformer模型 """
def __init__(
self, n_src_vocab, n_trg_vocab, src_pad_idx, trg_pad_idx,
d_word_vec=512, d_model=512, d_inner=2048,
n_layers=6, n_head=8, d_k=64, d_v=64, dropout=0.1, n_position=200,
trg_emb_prj_weight_sharing=True, emb_src_trg_weight_sharing=True):
"""
初始化Transformer模型
n_src_vocab: 源词汇表的大小
n_trg_vocab: 目标词汇表的大小
src_pad_idx: 源序列的填充索引
trg_pad_idx: 目标序列的填充索引
d_word_vec: 词向量的维度(默认值为512)
d_model: 模型的维度(默认值为512)
d_inner: 内部前馈层的维度(默认值为2048)
n_layers: 编码器和解码器层的数量(默认值为6)
n_head: 注意力头的数量(默认值为8)
d_k: 键的维度(默认值为64)
d_v: 值的维度(默认值为64)
dropout: Dropout率(默认值为0.1)
n_position: 位置编码的数量(默认值为200)
trg_emb_prj_weight_sharing: 是否共享目标词嵌入和最后一层的权重(默认值为True)
emb_src_trg_weight_sharing: 是否共享源词嵌入和目标词嵌入的权重(默认值为True)
"""
super().__init__()
self.src_pad_idx, self.trg_pad_idx = src_pad_idx, trg_pad_idx # 初始化源和目标序列的填充索引
# 初始化编码器
self.encoder = Encoder(
n_src_vocab=n_src_vocab, n_position=n_position,
d_word_vec=d_word_vec, d_model=d_model, d_inner=d_inner,
n_layers=n_layers, n_head=n_head, d_k=d_k, d_v=d_v,
pad_idx=src_pad_idx, dropout=dropout)
# 初始化解码器
self.decoder = Decoder(
n_trg_vocab=n_trg_vocab, n_position=n_position,
d_word_vec=d_word_vec, d_model=d_model, d_inner=d_inner,
n_layers=n_layers, n_head=n_head, d_k=d_k, d_v=d_v,
pad_idx=trg_pad_idx, dropout=dropout)
self.trg_word_prj = nn.Linear(d_model, n_trg_vocab, bias=False) # 初始化目标词投影层
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p) # 使用Xavier均匀初始化参数
assert d_model == d_word_vec, \
'为了便于残差连接,所有模块输出的维度应相同。'
self.x_logit_scale = 1.
if trg_emb_prj_weight_sharing:
# 共享目标词嵌入和最后一层的权重
self.trg_word_prj.weight = self.decoder.trg_word_emb.weight
self.x_logit_scale = (d_model ** -0.5)
if emb_src_trg_weight_sharing:
# 共享源词嵌入和目标词嵌入的权重
self.encoder.src_word_emb.weight = self.decoder.trg_word_emb.weight
def forward(self, src_seq, trg_seq):
"""
前向传播函数
src_seq: 源序列
trg_seq: 目标序列
"""
src_mask = get_pad_mask(src_seq, self.src_pad_idx) # 获取源序列的填充掩码
trg_mask = get_pad_mask(trg_seq, self.trg_pad_idx) & get_subsequent_mask(trg_seq) # 获取目标序列的填充掩码和后续掩码
enc_output, *_ = self.encoder(src_seq, src_mask) # 通过编码器获取编码器输出
dec_output, *_ = self.decoder(trg_seq, trg_mask, enc_output, src_mask) # 通过解码器获取解码器输出
seq_logit = self.trg_word_prj(dec_output) * self.x_logit_scale # 通过目标词投影层并进行缩放
#seq_logit: (batch_size, seq_len, vocab_size)
#seq_logit.size(2) 获取 seq_logit 在第三个维度上的大小,即 vocab_size
#view(-1, seq_logit.size(2)) 将 seq_logit 的形状调整为 (batch_size * seq_len, vocab_size)
return seq_logit.view(-1, seq_logit.size(2)) # 返回序列的logits
评论区