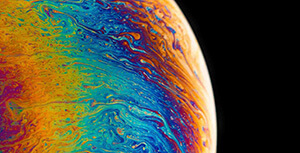

论文名称:An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale
背景
Transformer是Google团队在2017年提出的一种用于解决NLP领域问题的一种新型架构,它与以往的seq2seq的不同之处是提出了一种Self-Attention机制。使得模型不仅能够获得全局的上下文信息,还能通过并行训练大大提高训练效率。可以说是完美的解决了传统RNN、LSTM网络的局限性。
算法流程
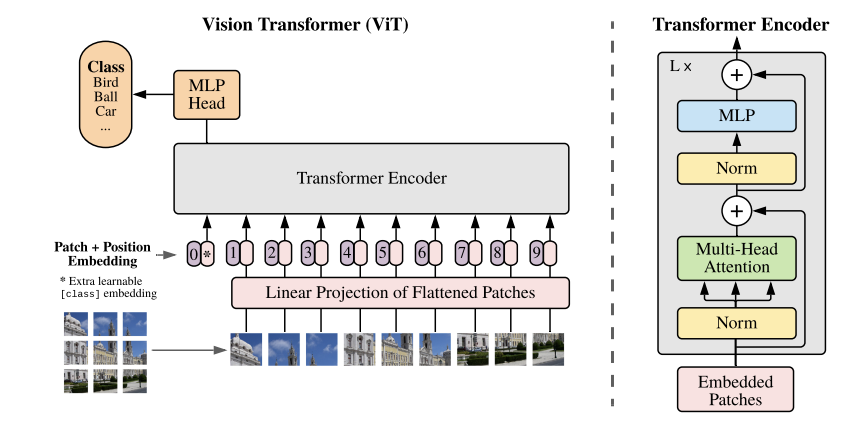
图像预处理
预处理步骤在论文中并未详细说明,但对于ViT结构而言,输入图片的尺寸是固定的。例如,ViT-B/16要求输入图片的尺寸必须为224x224。
因此,首先需要对输入图片进行尺寸调整。具体方法可以是直接缩放(Resize),也可以采用随机裁剪(RandomResizedCrop)。在后续的复现代码中,我们使用的是随机裁剪的方式。
图片分割
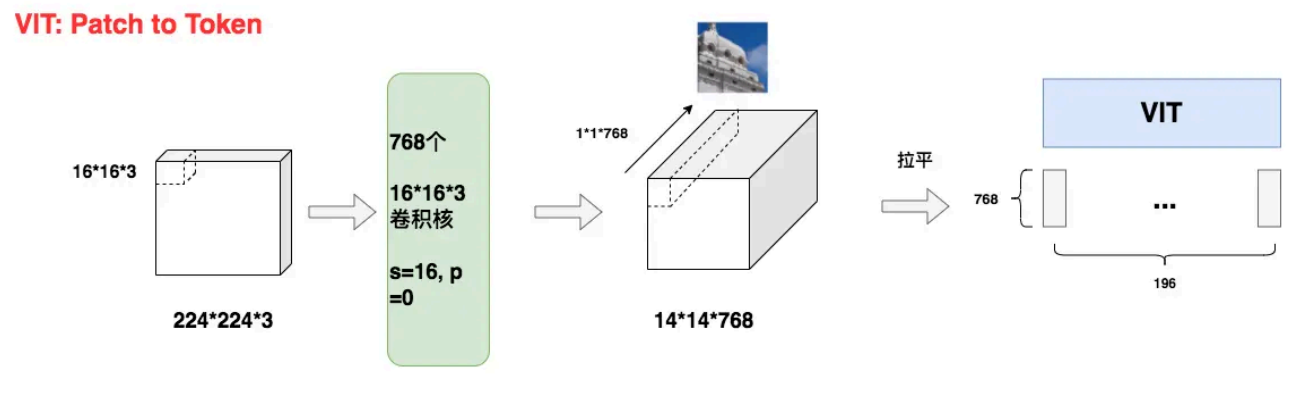
Transformer的输入为一维的Token,而对于二维图像,一种简单的处理方式是将每个像素点拉平,形成一维序列。然而,这种方法会导致计算量过于庞大。例如,一张224x224的图片拉平后会变成50176个Token,相当于直接输入一篇五万字的文章,令模型难以处理。为了解决这一问题,可以将图片划分为nxn个Patch,每个Patch作为一个Token,从而显著减少计算量。
以ViT-B/16为例,输入的224x224图片被划分为16x16大小的Patch,最终得到(224 / 16)² = 196个Patch。每个Patch是一个三通道的小图像,形状为(16, 16, 3),展平后变成长度为768的向量。这样,我们总共有196个向量,可以在代码中表示为一个[196, 768]的矩阵,进行并行输入。
在论文中,这一步骤采用了直接切割的方法,而在后续的代码实现中,采用了一种更巧妙的方式,即利用一个大小为16x16、步距为16、卷积核个数为768的卷积层来实现这一过程。
CLS Token
在上述结构图中,可以看到输入Encoder的最左侧部分添加了一个0*的Token,这个Token是额外添加的[class] token,专门用于处理类别信息。经过Encoder处理后,需要单独提取出这个Token,并将其输入到MLP Head中以输出分类结果。因此,结构图中MLP Head的位置与[class] token是对齐的。
位置编码
在Transformer中,位置编码的主要作用是记忆输入的语序信息。在ViT中,同样需要位置编码来记录各图像块之间的位置信息。
主要有两种位置编码的思路:一种是在转换之前对(14,14)的图像块矩阵添加二维(2-D)位置编码,另一种是在转换后对(196+1)的维度添加一维(1-D)位置编码。
作者进行了相关实验,实验结果如下表所示:
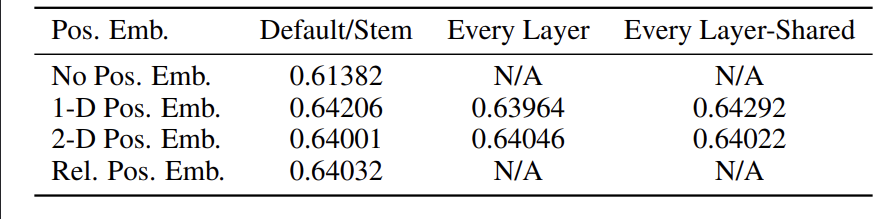
从结果中可以看出,添加一维位置编码与二维位置编码之间并没有显著差异。随后,作者对一维位置编码的结果进行了可视化,结果如下图所示:
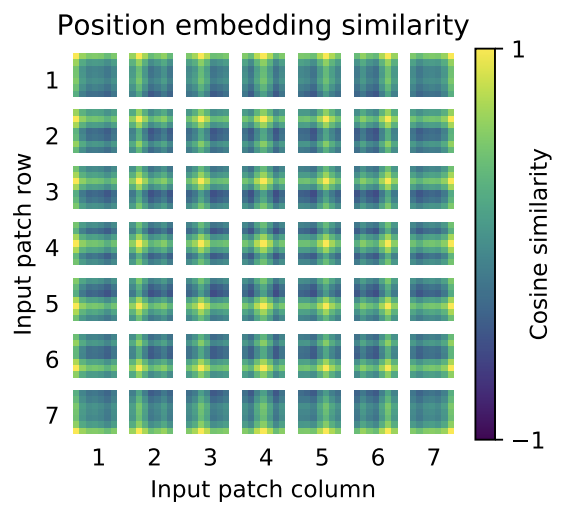
上图展示了每个 Patch 中各位置的编码相似性度量。越接近黄色的位置表示越接近位置编码的中心。可以看出,即使是一维位置编码,依然能够有效地记录二维信息。
Encoder
ViT虽然采用的是Transformer Encoder的结构,但是和Transformer原始的Encoder还是有所区别,如下图所示,左侧为Transformer原始的Encoder结构。
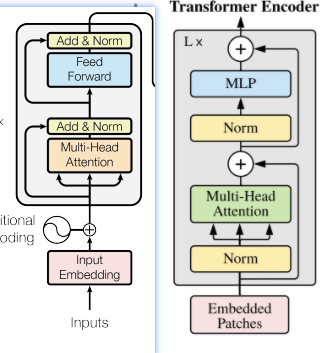
可以看到,大致上两者结构是相同的,主要区别在于Norm层的顺序,原始Transformer的Norm层在多头注意力和前馈网络之后,而ViT将其放到前面,这里的原因,论文里没有做解释。关于Norm层,VIT仍采用的是Layer Normlaization。
MLP
MLP采用两个线性层+GELU激活函数+Dropout正则化的结构。
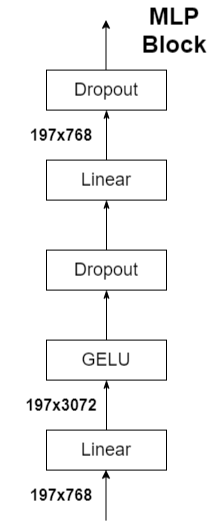
输入维度变化
对于输入(1,3,224,224)和使用 patch size 为 16 的设置,维度变化的步骤可以总结为以下过程:
1.图像块的提取:
使用 patch size 为 (16, 16) 将输入图像划分为图像块。
(224/16)*(224/16)=14*14=196个图像块,对应image_sequence_length
维度变为(1,196,3,16,16)。
2.展平成向量:
将每个图像块展平为长度为 16*16*3 的向量。
维度变为(1,196,768)。
3.加入 Class Token 和 位置嵌入:
添加 Class Token(1*768),将维度变为(1,197,768)。
添加位置嵌入(相加),最终维度仍为(1,197,768)。

4.线性投影:
使用线性投影将维度投影到 output_dim=768(可变)。对应input_dim
维度仍为(1,197,768)。

5.transformer
1.多头自注意力机制(Multi-Head Self-Attention):
1.如果默认的头数是 h(通常为 12),并且头维度(head dim)是 d_h(通常为 64),则每个头产生的输出维度为(1,12,64)。embed_dim对应d_h*h
2.线性变换得到 Q, K, V:
1.对输入进行三个线性变换,得到Q,K,V,每个变换的权重矩阵维度为 (d_model,d_h*h)即(1024->12x64=768)。h为头的个数
2.Q 的维度为 (1,197,768),K 的维度为 (1,197,768),V 的维度为 (1,197,768)。
3.这可以用矩阵相乘的方式实现:Q=X⋅Wq,K=X⋅Wk,V=X⋅Wv,其中 X 是输入张量。
3.拆分为多头:
1.将得到的 Q,K,V 分别拆分为 h 个头,每个头的维度为 (1,197,64)。
2.这里的拆分是在最后一维上进行的。
4.注意力计算:
1.对每个头进行注意力计算,得到注意力分数。
2.注意力计算包括对 Q 和 K 进行点积,然后进行缩放操作,最后应用 softmax 函数。
3.将注意力分数乘以 V,得到每个头的注意力输出(1,197,64)。
5.合并多头输出:
1.将每个头的注意力输出按最后一维度进行连接(concatenate),得到多头注意力的输出。
2.多头注意力的输出的维度为 (1,197,768)。这里768=h*d_h(12*64)
3.经过映射为(1,197,768)
6.加残差,维度不变(1,197,768)

2.LayerNormalization 和 Feedforward:
1.对于每个位置,进行 LayerNormalization 维度不变(1,197,768)。
2.Feedforward 网络:
1.如果默认的 Feedforward 网络的中间维度为 3072(一般默认扩大4倍)):
1.输入维度:(1,197,768)
2.变化为:(1,197,3072)
3.输出维度:(1,197,768)
3.加残差,维度不变(1,197,768)
6.(1,197,768)全局池化或者只取cls token(1,768)
代码解析
drop path正则化
def drop_path(x, drop_prob: float = 0., training: bool = False):
"""
Drop paths(随机深度)每个样本(当应用于残差块的主路径时)
“生存率”作为参数。
"""
if drop_prob == 0. or not training:
return x # 如果drop_prob为0或不在训练模式下,直接返回输入x
keep_prob = 1 - drop_prob # 计算保持概率
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # 生成与输入x相同维度的形状,但在除第一个维度外的其他维度上为1
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device) # 生成一个随机张量
random_tensor.floor_() # 将随机张量二值化
output = x.div(keep_prob) * random_tensor # 缩放输入x并与随机张量相乘
return output # 返回经过drop path处理后的输出
class DropPath(nn.Module):
"""
Drop paths(随机深度)每个样本(当应用于残差块的主路径时)
"""
def __init__(self, drop_prob=None):
"""
初始化DropPath模块
drop_prob: float, 随机深度的概率
"""
super(DropPath, self).__init__()
self.drop_prob = drop_prob # 设置drop_prob属性
def forward(self, x):
"""
前向传播函数
x: torch.Tensor, 输入张量
"""
return drop_path(x, self.drop_prob, self.training) # 调用drop_path函数并返回结果Patch嵌入
class PatchEmbed(nn.Module):
"""
2D图像到Patch嵌入
"""
def __init__(self, img_size=224, patch_size=16, in_c=3, embed_dim=768, norm_layer=None):
"""
初始化PatchEmbed模块
img_size: int, 输入图像的大小
patch_size: int, patch的大小
in_c: int, 输入通道数
embed_dim: int, 嵌入维度
norm_layer: nn.Module, 归一化层
"""
super().__init__()
img_size = (img_size, img_size) # 将图像大小转换为元组
patch_size = (patch_size, patch_size) # 将patch大小转换为元组
self.img_size = img_size # 设置图像大小
self.patch_size = patch_size # 设置patch大小
self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1]) # 计算网格大小
self.num_patches = self.grid_size[0] * self.grid_size[1] # 计算patch数量
self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size) # 定义卷积层用于投影
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity() # 定义归一化层,如果未提供则使用Identity
def forward(self, x):
"""
前向传播函数
x: torch.Tensor, 输入张量
"""
B, C, H, W = x.shape # 获取输入张量的形状
assert H == self.img_size[0] and W == self.img_size[1], \
f"输入图像大小 ({H}*{W}) 与模型不匹配 ({self.img_size[0]}*{self.img_size[1]})." # 确保输入图像大小与模型匹配
# flatten: [B, C, H, W] -> [B, C, HW]
# transpose: [B, C, HW] -> [B, HW, C]
x = self.proj(x).flatten(2).transpose(1, 2) # 通过卷积层投影并展平和转置
x = self.norm(x) # 通过归一化层
return x # 返回嵌入后的张量注意力机制
class Attention(nn.Module):
def __init__(self,
dim, # 输入token的维度
num_heads=8, # 注意力头的数量
qkv_bias=False, # 是否在qkv线性层中使用偏置
qk_scale=None, # 缩放因子,如果为None则使用默认值
attn_drop_ratio=0., # 注意力权重的dropout比例
proj_drop_ratio=0.): # 输出的dropout比例
super(Attention, self).__init__()
self.num_heads = num_heads # 设置注意力头的数量
head_dim = dim // num_heads # 每个头的维度
self.scale = qk_scale or head_dim ** -0.5 # 设置缩放因子
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias) # 定义qkv线性层
self.attn_drop = nn.Dropout(attn_drop_ratio) # 定义注意力权重的dropout层
self.proj = nn.Linear(dim, dim) # 定义输出的线性层
self.proj_drop = nn.Dropout(proj_drop_ratio) # 定义输出的dropout层
def forward(self, x):
# x的形状为[batch_size, num_patches + 1, total_embed_dim]
B, N, C = x.shape # 获取输入x的形状
# qkv(): -> [batch_size, num_patches + 1, 3 * total_embed_dim]
# reshape: -> [batch_size, num_patches + 1, 3, num_heads, embed_dim_per_head]
# permute: -> [3, batch_size, num_heads, num_patches + 1, embed_dim_per_head]
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
# 分别获取q, k, v的值,形状为[batch_size, num_heads, num_patches + 1, embed_dim_per_head]
q, k, v = qkv[0], qkv[1], qkv[2] # 使torchscript happy(不能将tensor用作元组)
# transpose: -> [batch_size, num_heads, embed_dim_per_head, num_patches + 1]
# @: multiply -> [batch_size, num_heads, num_patches + 1, num_patches + 1]
attn = (q @ k.transpose(-2, -1)) * self.scale # 计算注意力权重
attn = attn.softmax(dim=-1) # 对注意力权重进行softmax
attn = self.attn_drop(attn) # 对注意力权重进行dropout
# @: multiply -> [batch_size, num_heads, num_patches + 1, embed_dim_per_head]
# transpose: -> [batch_size, num_patches + 1, num_heads, embed_dim_per_head]
# reshape: -> [batch_size, num_patches + 1, total_embed_dim]
x = (attn @ v).transpose(1, 2).reshape(B, N, C) # 计算注意力输出
x = self.proj(x) # 通过输出的线性层
x = self.proj_drop(x) # 通过输出的dropout层
return x # 返回注意力输出MLP多层感知机
class Mlp(nn.Module):
"""
MLP as used in Vision Transformer, MLP-Mixer and related networks
多层感知机(MLP),用于视觉Transformer、MLP-Mixer和相关网络
"""
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
"""
初始化MLP模块
in_features: int, 输入特征的维度
hidden_features: int, 隐藏层特征的维度,如果为None则与in_features相同
out_features: int, 输出特征的维度,如果为None则与in_features相同
act_layer: nn.Module, 激活层,默认为GELU
drop: float, Dropout的概率,默认为0
"""
super().__init__()
out_features = out_features or in_features # 如果out_features为None,则设置为in_features
hidden_features = hidden_features or in_features # 如果hidden_features为None,则设置为in_features
self.fc1 = nn.Linear(in_features, hidden_features) # 定义第一个全连接层
self.act = act_layer() # 定义激活层
self.fc2 = nn.Linear(hidden_features, out_features) # 定义第二个全连接层
self.drop = nn.Dropout(drop) # 定义Dropout层
def forward(self, x):
"""
前向传播函数
x: torch.Tensor, 输入张量
"""
x = self.fc1(x) # 通过第一个全连接层
x = self.act(x) # 通过激活层
x = self.drop(x) # 通过Dropout层
x = self.fc2(x) # 通过第二个全连接层
x = self.drop(x) # 再次通过Dropout层
return x # 返回输出张量VIT Block
class Block(nn.Module):
def __init__(self,
dim, # 输入token的维度
num_heads, # 注意力头的数量
mlp_ratio=4., # MLP隐藏层的维度与输入维度的比例
qkv_bias=False, # 是否在qkv线性层中使用偏置
qk_scale=None, # 缩放因子,如果为None则使用默认值
drop_ratio=0., # Dropout的概率
attn_drop_ratio=0., # 注意力权重的Dropout概率
drop_path_ratio=0., # 随机深度的概率
act_layer=nn.GELU, # 激活层,默认为GELU
norm_layer=nn.LayerNorm): # 归一化层,默认为LayerNorm
super(Block, self).__init__()
self.norm1 = norm_layer(dim) # 定义第一个归一化层
self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop_ratio=attn_drop_ratio, proj_drop_ratio=drop_ratio) # 定义注意力层
self.drop_path = DropPath(drop_path_ratio) if drop_path_ratio > 0. else nn.Identity() # 定义随机深度层,如果drop_path_ratio为0则使用Identity
self.norm2 = norm_layer(dim) # 定义第二个归一化层
mlp_hidden_dim = int(dim * mlp_ratio) # 计算MLP隐藏层的维度
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop_ratio) # 定义MLP层
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x))) # 通过第一个归一化层、注意力层和随机深度层,并进行残差连接
x = x + self.drop_path(self.mlp(self.norm2(x))) # 通过第二个归一化层、MLP层和随机深度层,并进行残差连接
return x # 返回输出Vision Transformer(VIT)
class VisionTransformer(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_c=3, num_classes=1000,
embed_dim=768, depth=12, num_heads=12, mlp_ratio=4.0, qkv_bias=True,
qk_scale=None, representation_size=None, distilled=False, drop_ratio=0.,
attn_drop_ratio=0., drop_path_ratio=0., embed_layer=PatchEmbed, norm_layer=None,
act_layer=None):
"""
初始化Vision Transformer模型
Args:
img_size (int, tuple): 输入图像大小
patch_size (int, tuple): patch的大小
in_c (int): 输入通道数
num_classes (int): 分类头的类别数
embed_dim (int): 嵌入维度
depth (int): Transformer的深度
num_heads (int): 注意力头的数量
mlp_ratio (int): MLP隐藏层维度与嵌入维度的比例
qkv_bias (bool): 是否在qkv中使用偏置
qk_scale (float): 缩放因子,如果设置则覆盖默认值head_dim ** -0.5
representation_size (Optional[int]): 如果设置,则启用并设置表示层(pre-logits)的值
distilled (bool): 模型是否包含一个蒸馏token和头部,如DeiT模型
drop_ratio (float): Dropout率
attn_drop_ratio (float): 注意力Dropout率
drop_path_ratio (float): 随机深度率
embed_layer (nn.Module): patch嵌入层
norm_layer: (nn.Module): 归一化层
"""
super(VisionTransformer, self).__init__()
self.num_classes = num_classes # 设置分类头的类别数
self.num_features = self.embed_dim = embed_dim # 设置嵌入维度
self.num_tokens = 2 if distilled else 1 # 设置token数量,如果蒸馏则为2,否则为1
norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6) # 设置归一化层,默认为LayerNorm
act_layer = act_layer or nn.GELU # 设置激活层,默认为GELU
self.patch_embed = embed_layer(img_size=img_size, patch_size=patch_size, in_c=in_c, embed_dim=embed_dim) # 初始化patch嵌入层
num_patches = self.patch_embed.num_patches # 获取patch数量
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) # 初始化分类token
self.dist_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) if distilled else None # 如果蒸馏,则初始化蒸馏token
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, embed_dim)) # 初始化位置嵌入
self.pos_drop = nn.Dropout(p=drop_ratio) # 初始化位置Dropout
dpr = [x.item() for x in torch.linspace(0, drop_path_ratio, depth)] # 计算随机深度衰减规则
self.blocks = nn.Sequential(*[
Block(dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop_ratio=drop_ratio, attn_drop_ratio=attn_drop_ratio, drop_path_ratio=dpr[i],
norm_layer=norm_layer, act_layer=act_layer)
for i in range(depth) # 初始化Transformer块
])
self.norm = norm_layer(embed_dim) # 初始化归一化层
# 表示层
if representation_size and not distilled:
self.has_logits = True # 设置是否有logits
self.num_features = representation_size # 设置表示层的特征数
self.pre_logits = nn.Sequential(OrderedDict([
("fc", nn.Linear(embed_dim, representation_size)), # 全连接层
("act", nn.Tanh()) # 激活层
]))
else:
self.has_logits = False # 没有logits
self.pre_logits = nn.Identity() # 表示层为Identity
# 分类头
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity() # 初始化分类头
self.head_dist = None # 初始化蒸馏头
if distilled:
self.head_dist = nn.Linear(self.embed_dim, self.num_classes) if num_classes > 0 else nn.Identity() # 如果蒸馏,则初始化蒸馏头
# 权重初始化
nn.init.trunc_normal_(self.pos_embed, std=0.02) # 初始化位置嵌入
if self.dist_token is not None:
nn.init.trunc_normal_(self.dist_token, std=0.02) # 初始化蒸馏token
nn.init.trunc_normal_(self.cls_token, std=0.02) # 初始化分类token
self.apply(_init_vit_weights) # 应用ViT权重初始化
def forward_features(self, x):
"""
提取特征
Args:
x: torch.Tensor, 输入张量
"""
x = self.patch_embed(x) # 通过patch嵌入层
cls_token = self.cls_token.expand(x.shape[0], -1, -1) # 扩展分类token
if self.dist_token is None:
x = torch.cat((cls_token, x), dim=1) # 拼接分类token
else:
x = torch.cat((cls_token, self.dist_token.expand(x.shape[0], -1, -1), x), dim=1) # 拼接分类token和蒸馏token
x = self.pos_drop(x + self.pos_embed) # 加上位置嵌入并应用Dropout
x = self.blocks(x) # 通过Transformer块
x = self.norm(x) # 通过归一化层
if self.dist_token is None:
return self.pre_logits(x[:, 0]) # 返回分类token的特征
else:
return x[:, 0], x[:, 1] # 返回分类token和蒸馏token的特征
def forward(self, x):
"""
前向传播
Args:
x: torch.Tensor, 输入张量
"""
x = self.forward_features(x) # 提取特征
if self.head_dist is not None:
x, x_dist = self.head(x[0]), self.head_dist(x[1]) # 通过分类头和蒸馏头
if self.training and not torch.jit.is_scripting():
return x, x_dist # 训练时返回分类头和蒸馏头的输出
else:
return (x + x_dist) / 2 # 推理时返回分类头和蒸馏头输出的平均值
else:
x = self.head(x) # 通过分类头
return x # 返回输出VIT初始化实例
def _init_vit_weights(m):
"""
ViT权重初始化
:param m: 模块
"""
if isinstance(m, nn.Linear):
nn.init.trunc_normal_(m.weight, std=.01) # 截断正态分布初始化线性层的权重
if m.bias is not None:
nn.init.zeros_(m.bias) # 将线性层的偏置初始化为零
elif isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out") # 使用Kaiming正态分布初始化卷积层的权重
if m.bias is not None:
nn.init.zeros_(m.bias) # 将卷积层的偏置初始化为零
elif isinstance(m, nn.LayerNorm):
nn.init.zeros_(m.bias) # 将LayerNorm层的偏置初始化为零
nn.init.ones_(m.weight) # 将LayerNorm层的权重初始化为一
def vit_base_patch16_224(num_classes: int = 1000):
"""
ViT-Base模型(ViT-B/16),来自原始论文(https://arxiv.org/abs/2010.11929)。
ImageNet-1k权重@224x224,来源https://github.com/google-research/vision_transformer。
权重从官方Google JAX实现中移植:
链接: https://pan.baidu.com/s/1zqb08naP0RPqqfSXfkB2EA 密码: eu9f
"""
model = VisionTransformer(img_size=224, # 输入图像大小
patch_size=16, # patch的大小
embed_dim=768, # 嵌入维度
depth=12, # Transformer的深度
num_heads=12, # 注意力头的数量
representation_size=None, # 表示层的大小
num_classes=num_classes) # 分类头的类别数
return model # 返回模型
def vit_base_patch16_224_in21k(num_classes: int = 21843, has_logits: bool = True):
"""
ViT-Base模型(ViT-B/16),来自原始论文(https://arxiv.org/abs/2010.11929)。
ImageNet-21k权重@224x224,来源https://github.com/google-research/vision_transformer。
权重从官方Google JAX实现中移植:
https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_base_patch16_224_in21k-e5005f0a.pth
"""
model = VisionTransformer(img_size=224, # 输入图像大小
patch_size=16, # patch的大小
embed_dim=768, # 嵌入维度
depth=12, # Transformer的深度
num_heads=12, # 注意力头的数量
representation_size=768 if has_logits else None, # 表示层的大小,如果有logits则为768
num_classes=num_classes) # 分类头的类别数
return model # 返回模型
def vit_base_patch32_224(num_classes: int = 1000):
"""
ViT-Base模型(ViT-B/32),来自原始论文(https://arxiv.org/abs/2010.11929)。
ImageNet-1k权重@224x224,来源https://github.com/google-research/vision_transformer。
权重从官方Google JAX实现中移植:
链接: https://pan.baidu.com/s/1hCv0U8pQomwAtHBYc4hmZg 密码: s5hl
"""
model = VisionTransformer(img_size=224, # 输入图像大小
patch_size=32, # patch的大小
embed_dim=768, # 嵌入维度
depth=12, # Transformer的深度
num_heads=12, # 注意力头的数量
representation_size=None, # 表示层的大小
num_classes=num_classes) # 分类头的类别数
return model # 返回模型
def vit_base_patch32_224_in21k(num_classes: int = 21843, has_logits: bool = True):
"""
ViT-Base模型(ViT-B/32),来自原始论文(https://arxiv.org/abs/2010.11929)。
ImageNet-21k权重@224x224,来源https://github.com/google-research/vision_transformer。
权重从官方Google JAX实现中移植:
https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_base_patch32_224_in21k-8db57226.pth
"""
model = VisionTransformer(img_size=224, # 输入图像大小
patch_size=32, # patch的大小
embed_dim=768, # 嵌入维度
depth=12, # Transformer的深度
num_heads=12, # 注意力头的数量
representation_size=768 if has_logits else None, # 表示层的大小,如果有logits则为768
num_classes=num_classes) # 分类头的类别数
return model # 返回模型
def vit_large_patch16_224(num_classes: int = 1000):
"""
ViT-Large模型(ViT-L/16),来自原始论文(https://arxiv.org/abs/2010.11929)。
ImageNet-1k权重@224x224,来源https://github.com/google-research/vision_transformer。
权重从官方Google JAX实现中移植:
链接: https://pan.baidu.com/s/1cxBgZJJ6qUWPSBNcE4TdRQ 密码: qqt8
"""
model = VisionTransformer(img_size=224, # 输入图像大小
patch_size=16, # patch的大小
embed_dim=1024, # 嵌入维度
depth=24, # Transformer的深度
num_heads=16, # 注意力头的数量
representation_size=None, # 表示层的大小
num_classes=num_classes) # 分类头的类别数
return model # 返回模型
def vit_large_patch16_224_in21k(num_classes: int = 21843, has_logits: bool = True):
"""
ViT-Large模型(ViT-L/16),来自原始论文(https://arxiv.org/abs/2010.11929)。
ImageNet-21k权重@224x224,来源https://github.com/google-research/vision_transformer。
权重从官方Google JAX实现中移植:
https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_large_patch16_224_in21k-606da67d.pth
"""
model = VisionTransformer(img_size=224, # 输入图像大小
patch_size=16, # patch的大小
embed_dim=1024, # 嵌入维度
depth=24, # Transformer的深度
num_heads=16, # 注意力头的数量
representation_size=1024 if has_logits else None, # 表示层的大小,如果有logits则为1024
num_classes=num_classes) # 分类头的类别数
return model # 返回模型
def vit_large_patch32_224_in21k(num_classes: int = 21843, has_logits: bool = True):
"""
ViT-Large模型(ViT-L/32),来自原始论文(https://arxiv.org/abs/2010.11929)。
ImageNet-21k权重@224x224,来源https://github.com/google-research/vision_transformer。
权重从官方Google JAX实现中移植:
https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_large_patch32_224_in21k-9046d2e7.pth
"""
model = VisionTransformer(img_size=224, # 输入图像大小
patch_size=32, # patch的大小
embed_dim=1024, # 嵌入维度
depth=24, # Transformer的深度
num_heads=16, # 注意力头的数量
representation_size=1024 if has_logits else None, # 表示层的大小,如果有logits则为1024
num_classes=num_classes) # 分类头的类别数
return model # 返回模型
def vit_huge_patch14_224_in21k(num_classes: int = 21843, has_logits: bool = True):
"""
ViT-Huge模型(ViT-H/14),来自原始论文(https://arxiv.org/abs/2010.11929)。
ImageNet-21k权重@224x224,来源https://github.com/google-research/vision_transformer。
注意:转换的权重目前不可用,太大无法在github上发布。
"""
model = VisionTransformer(img_size=224, # 输入图像大小
patch_size=14, # patch的大小
embed_dim=1280, # 嵌入维度
depth=32, # Transformer的深度
num_heads=16, # 注意力头的数量
representation_size=1280 if has_logits else None, # 表示层的大小,如果有logits则为1280
num_classes=num_classes) # 分类头的类别数
return model # 返回模型
评论区