
论文名称:Deep Residual Learning for Image Recognition
背景
随着神经网络的深度不断加深,阻挡网络性能的两座大山——“梯度消失”和“梯度爆炸”成了迫切需要解决的问题。因此残差网络(ResNet)应运而生。ResNet由微软研究所的何凯明等大佬提出,目前该论文的引用量在谷歌学术上已经超过24W,可见其对深度神经网络的发展可以说是影响深远。其核心是通过残差连接,巧妙的解决了深层网络训练中的梯度消失和梯度爆炸的问题,如今的模型多多少少都借鉴了或者说可以看到残差网络的影子。

退化
随着神经网络层数的增加,网络性能反而不增反降的情况,我们称之为退化。造成模型退化的原因主要有以下几个方面。
1.梯度问题
梯度消失:若每一层的误差梯度小于1,反向传播时,网络越深,梯度越趋近于0。
梯度爆炸:若每一层的误差梯度大于1,反向传播时,网络越深,梯度越来越大。
随着网络层数的加深,根据反向传播中的链式法则,梯度会在传播的过程中逐渐减小,到最终甚至接近为零,以至于几乎不再会对权重有任何显著更新,影响模型的性能。某些激活函数(sigmod函数)的梯度在输入值原理中心点时会变得非常小,也会导致梯度消失。
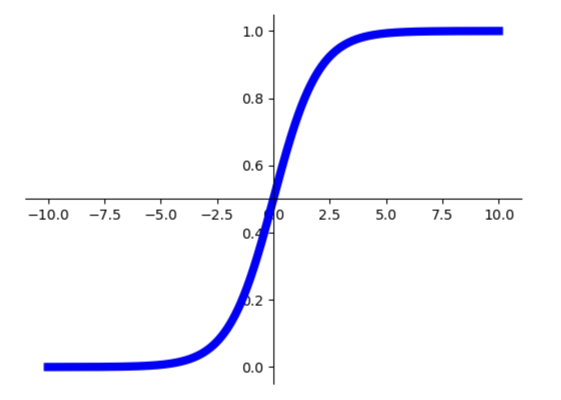
梯度爆炸产生的原因与梯度消失类似,因为梯度较大所以在链式传播过程中会造成梯度逐步放大,最终导致权重更新幅度巨大,造成模型不问题。
2.过拟合
过拟合是令人们十分苦恼的一个问题,因为深度神经网络强大的表达能力,在模型训练时容易在训练的过程中学习到过于细微的特征表达,脱离了实际情况。导致在训练的过程中精度不断提高,但是在测试的过程中反而出现性能下降的情况。
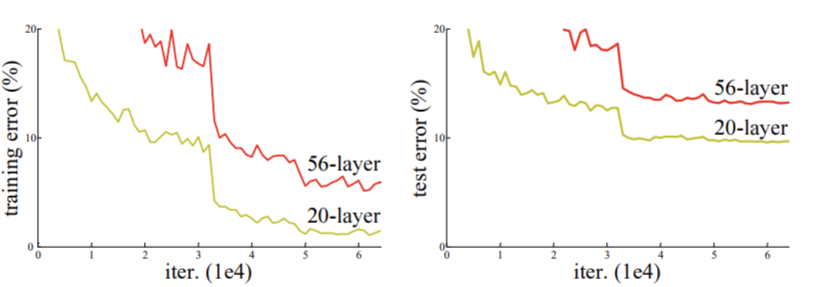
为了解决上述问题,学者们提出了采用合理的参数初始化和归一化方法、采用数据增强和drop out等正则化、改变激活函数、自适应学习绿等多种解决方案。而最有代表性的则是残差网络。
残差学习
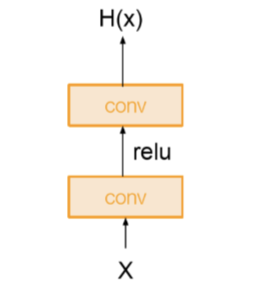
残差网络通过跳跃连接的方式引入了恒等映射。在以往的网络模型中,假设输入为X,在经过两层卷积层和激活层之后输出为H(X),此时输出H(X)就等于经过两层卷积和激活后的F(x)。而在残差网络中,添加了一个跳跃连接到第二层激活函数之前,此时激活函数的输入就变成了H(x)=F(x)+X,这就是残差网络的关键所在。即使出现最差的情况:这些网络层什么也没有学习,那么也只是复制浅层网络中的特征,此时F(x)=0,H(x)=X,不会丢失原本浅层网络的信息,至少不会让网络出现退化的情况。
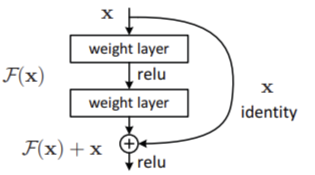
网络结构
ResNet block
ResNet block有两种,一种两层的BasicBlock结构,一种是三层的bottleneck结构,即将两个的卷积层替换为1*1+3*3+1*1,它通过卷积来巧妙地缩减feature map维度,从而使得我们的conv的filters数目不受上一层输入的影响,它的输出也不会影响到下一层。中间的卷积层首先在一个降维卷积层下减少了计算,然后在另一个的卷积层下做了还原。既保持了模型精度又减少了网络参数和计算量,节省了计算时间。
CNN参数个数 = 卷积核尺寸×卷积核深度 × 卷积核组数 = 卷积核尺寸 × 输入特征矩阵深度 × 输出特征矩阵深度
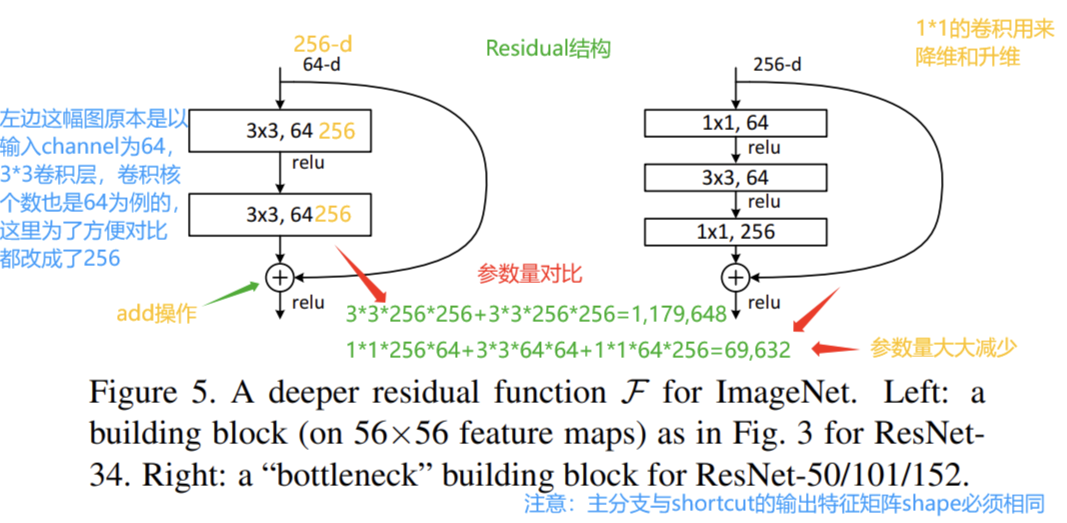
对于跳跃连接,如何残差映射F(x)与跳跃连接x的纬度不同,则需要进行升维操作以匹配跳跃连接的维度,通常使用卷积层来实现升维。
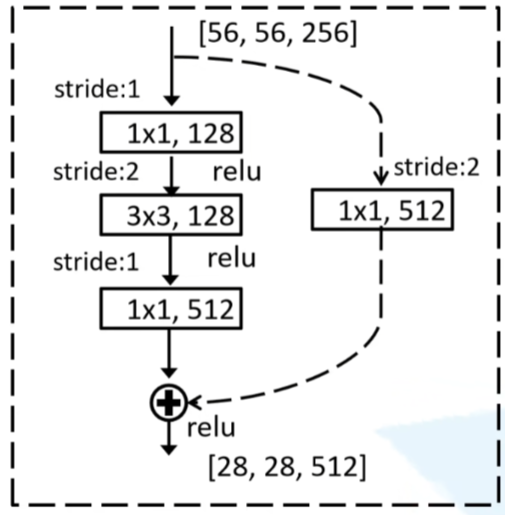
结构
ResNet网络是参考了VGG19网络,在其基础上进行了修改,并通过短路机制加入了残差单元,如下图所示。变化主要体现在ResNet直接使用stride=2的卷积做下采样,并且用global average pool层替换了全连接层。ResNet的一个重要设计原则是:输入尺寸减半,通道数加倍,这样保持了网络层的复杂度。
.png)
ResNet相比普通网络每两层间增加了短路机制,这就形成了残差学习,其中虚线表示feature map数量发生了改变,即使用了虚线残差结构,通过1*1卷积来改变维度。从表中可以看到,对于18-layer和34-layer的ResNet,其进行的两层间的残差学习,当网络更深时,其进行的是三层间的残差学习,三层卷积核分别是1x1,3x3和1x1。
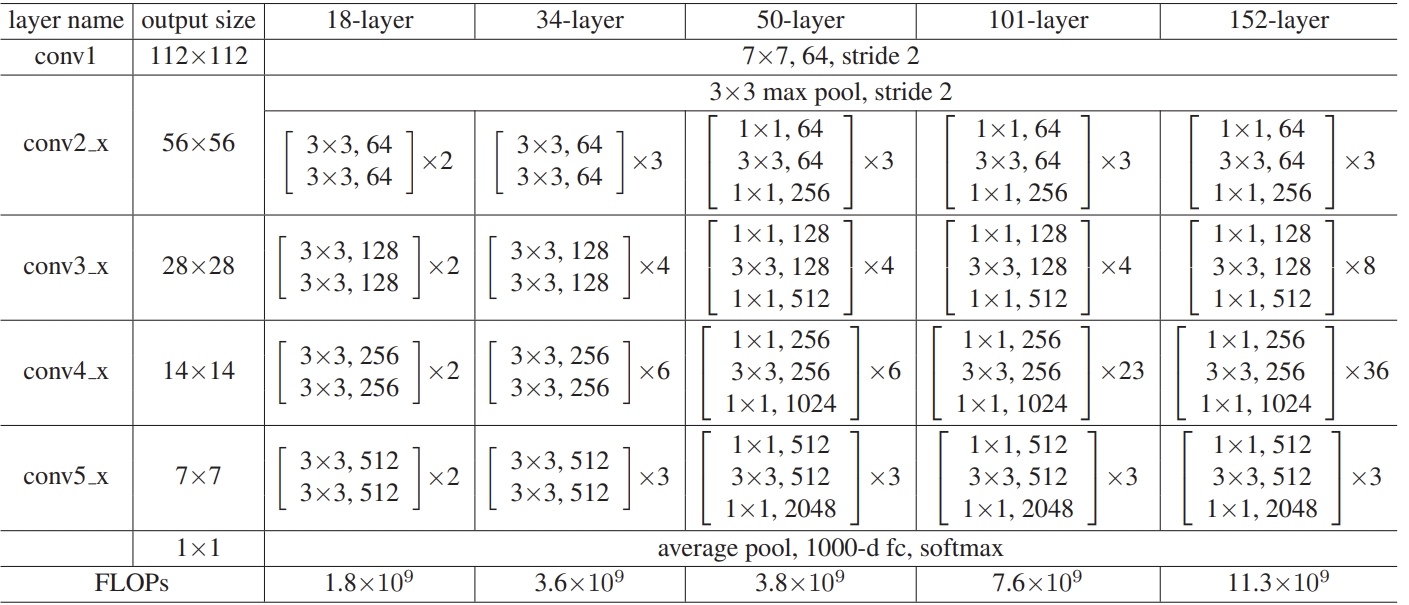
对于每一种残差网络结构,都是先经过一个7*7的卷积层,然后经过3*3的最大池化下采样操作,以降低特征图的尺寸。然后经过不同的卷积操作,最后再通过平均池化层、全连接层、softmax输出。
以Resnet-18为例,看一下具体的输入输出特征图大小
.png)
首先一张尺寸大小为224*224的RGB图片,再经过卷积核大小为7*7,步长为2,padding为2,卷积核数量为64的卷积层之后,尺寸变成112*112*64。
其中输出图像大小的计算公式为:(输入尺寸-卷积核大小+2*padding / 步长) + 1
再通过步长为2,padding为1,大小为3*3的最大池化层,尺寸变成56*56*64
再通过两个步长为1,padding为1,大小为3*3的卷积层,尺寸不变
再引入跳跃连接,再经过两个相同的卷积层,引入跳跃连接(每通过两个卷积层,引入一次跳跃连接)
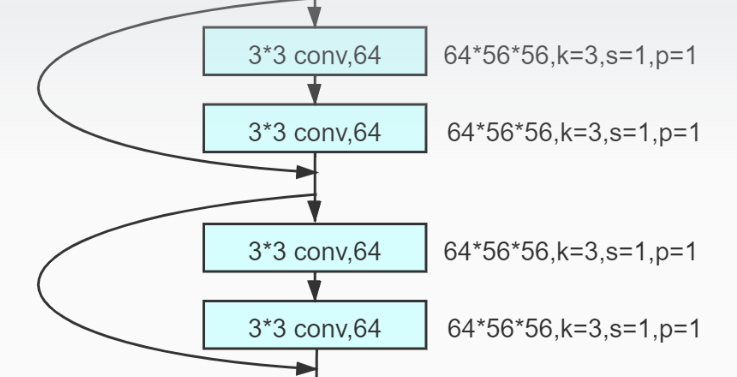
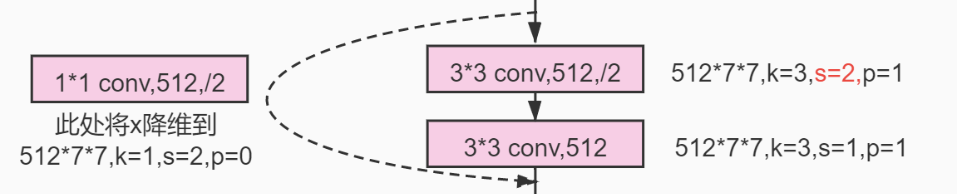
再通过一个步长为2,padding为1,大小为3*3,数量为128的卷积层(上文提到过的尺寸减半,通道数翻倍),将输入尺寸变为28*28*128

如此反复操作....尺寸变成14*14*256、7*7*512....

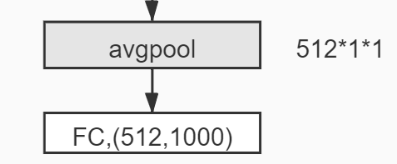
然后通过平均池化层,全连接层,尺寸变为1*1*512、1000*512
代码解析
Basicblock
import torch
import torch.nn as nn
class BasicBlock(nn.Module):
"""搭建BasicBlock模块"""
expansion = 1
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
super(BasicBlock, self).__init__()
# 使用BN层是不需要使用bias的,bias最后会抵消掉
self.conv1 = nn.Conv2d(in_channel, out_channel, kernel_size=3, padding=1, stride=stride, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel) # BN层, BN层放在conv层和relu层中间使用
self.conv2 = nn.Conv2d(out_channel, out_channel, kernel_size=3, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
self.relu = nn.ReLU(inplace=True)
# 前向传播
def forward(self, X):
identity = X
Y = self.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.downsample is not None: # 保证原始输入X的size与主分支卷积后的输出size叠加时维度相同
identity = self.downsample(X)
return self.relu(Y + identity)BottleNeck
class BottleNeck(nn.Module):
"""搭建BottleNeck模块"""
# BottleNeck模块最终输出out_channel是Residual模块输入in_channel的size的4倍(Residual模块输入为64),shortcut分支in_channel
# 为Residual的输入64,因此需要在shortcut分支上将Residual模块的in_channel扩张4倍,使之与原始输入图片X的size一致
expansion = 4
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
super(BottleNeck, self).__init__()
# 默认原始输入为256,经过7x7层和3x3层之后BottleNeck的输入降至64
self.conv1 = nn.Conv2d(in_channel, out_channel, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel) # BN层, BN层放在conv层和relu层中间使用
self.conv2 = nn.Conv2d(out_channel, out_channel, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.conv3 = nn.Conv2d(out_channel, out_channel * self.expansion, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_channel * self.expansion) # Residual中第三层out_channel扩张到in_channel的4倍
self.downsample = downsample
self.relu = nn.ReLU(inplace=True)
# 前向传播
def forward(self, X):
identity = X
Y = self.relu(self.bn1(self.conv1(X)))
Y = self.relu(self.bn2(self.conv2(Y)))
Y = self.bn3(self.conv3(Y))
if self.downsample is not None: # 保证原始输入X的size与主分支卷积后的输出size叠加时维度相同
identity = self.downsample(X)
return self.relu(Y + identity)ResNet
class ResNet(nn.Module):
"""搭建ResNet-layer通用框架"""
# num_classes是训练集的分类个数,include_top是在ResNet的基础上搭建更加复杂的网络时用到,此处用不到
def __init__(self, residual, num_residuals, num_classes=1000, include_top=True):
super(ResNet, self).__init__()
self.out_channel = 64 # 输出通道数(即卷积核个数),会生成与设定的输出通道数相同的卷积核个数
self.include_top = include_top
self.conv1 = nn.Conv2d(3, self.out_channel, kernel_size=7, stride=2, padding=3,
bias=False) # 3表示输入特征图像的RGB通道数为3,即图片数据的输入通道为3
self.bn1 = nn.BatchNorm2d(self.out_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.conv2 = self.residual_block(residual, 64, num_residuals[0])
self.conv3 = self.residual_block(residual, 128, num_residuals[1], stride=2)
self.conv4 = self.residual_block(residual, 256, num_residuals[2], stride=2)
self.conv5 = self.residual_block(residual, 512, num_residuals[3], stride=2)
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output_size = (1, 1)
self.fc = nn.Linear(512 * residual.expansion, num_classes)
# 对conv层进行初始化操作
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def residual_block(self, residual, channel, num_residuals, stride=1):
downsample = None
# 用在每个conv_x组块的第一层的shortcut分支上,此时上个conv_x输出out_channel与本conv_x所要求的输入in_channel通道数不同,
# 所以用downsample调整进行升维,使输出out_channel调整到本conv_x后续处理所要求的维度。
# 同时stride=2进行下采样减小尺寸size,(注:conv2时没有进行下采样,conv3-5进行下采样,size=56、28、14、7)。
if stride != 1 or self.out_channel != channel * residual.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.out_channel, channel * residual.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * residual.expansion))
block = [] # block列表保存某个conv_x组块里for循环生成的所有层
# 添加每一个conv_x组块里的第一层,第一层决定此组块是否需要下采样(后续层不需要)
block.append(residual(self.out_channel, channel, downsample=downsample, stride=stride))
self.out_channel = channel * residual.expansion # 输出通道out_channel扩张
for _ in range(1, num_residuals):
block.append(residual(self.out_channel, channel))
# 非关键字参数的特征是一个星号*加上参数名,比如*number,定义后,number可以接收任意数量的参数,并将它们储存在一个tuple中
return nn.Sequential(*block)
# 前向传播
def forward(self, X):
Y = self.relu(self.bn1(self.conv1(X)))
Y = self.maxpool(Y)
Y = self.conv5(self.conv4(self.conv3(self.conv2(Y))))
if self.include_top:
Y = self.avgpool(Y)
Y = torch.flatten(Y, 1)
Y = self.fc(Y)
return YResNet-34、ResNet-50
# 构建ResNet-34模型
def resnet34(num_classes=1000, include_top=True):
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
# 构建ResNet-50模型
def resnet50(num_classes=1000, include_top=True):
return ResNet(BottleNeck, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
# 模型网络结构可视化
net = resnet34()
评论区