
注:本文摘抄自论文《Transformer for Object Re-Identification: A Survey》
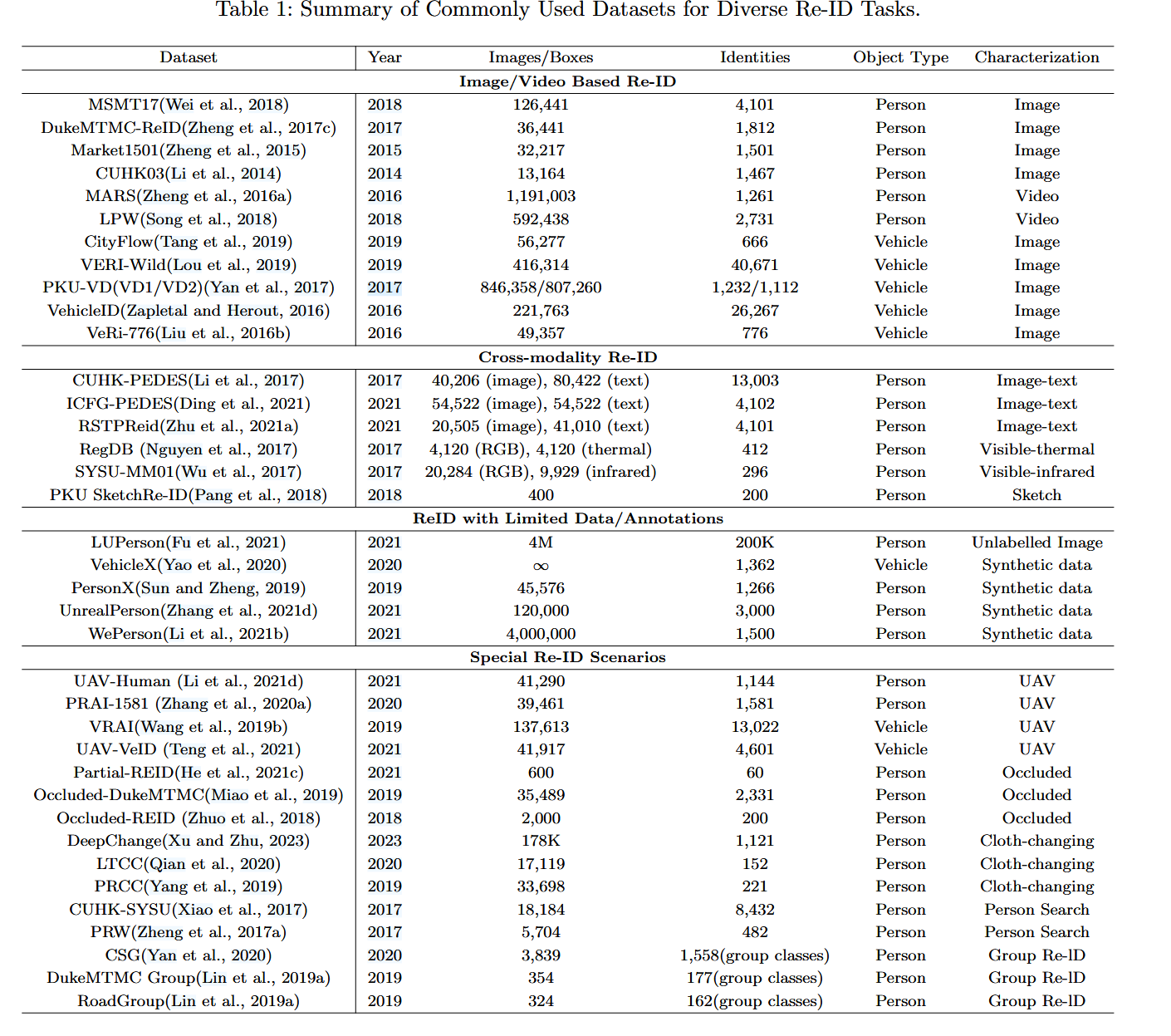
行人重识别常用数据集
相关工作
S. He et al., “TransReID: Transformer-based object re-identification,” in Proc. IEEE/CVF Int. Conf. Comput. Vis., 2021, pp. 15013–15022.
K. Zhu et al., “AAformer: Auto-aligned transformer for person reidentification,” IEEE Trans. Neural Netw. Learn. Syst., early access, Aug. 25, 2023, doi: 10.1109/TNNLS.2023.3301856.
H. Ma, X. Li, X. Yuan, and C. Zhao, “Denseformer: A dense transformer framework for person re-identification,” IET Comput. Vis., vol. 17, no. 5, pp. 527–536, 2022.
M. Jia, X. Cheng, S. Lu, and J. Zhang, “Learning disentangled representation implicitly via transformer for occluded person re-identification,” IEEE Trans. Multimedia, vol. 25, pp. 1294–1305, 2023.
L. Shen, T. He, Y. Guo, and G. Ding, “X-ReID: Crossinstance transformer for identity-level person re-identification,” 2023, arXiv:2302.02075.
Y. Lu, M. Jiang, Z. Liu, and X. Mu, “Dual-branch adaptive attention transformer for occluded person re-identification,” Image Vis. Comput., vol. 131, 2023, Art. no. 104633.
C. Chen, M. Ye, M. Qi, J. Wu, J. Jiang, and C.-W. Lin, “Structure-aware positional transformer for visible-infrared person re-identification,” IEEE Trans. Image Process., vol. 31, pp. 2352–2364, 2022.
Y. Li and Y. Chen, “Infrared-visible cross-modal person re-identification via dual-attention collaborative learning,” Signal Process.: Image Commun., vol. 109, 2022, Art. no. 116868.
Y. Feng et al., “Visible-infrared person re-identification via crossmodality interaction transformer,” IEEE Trans. Multimedia, vol. 25, pp. 7647–7659, 2023.
K. Jiang, T. Zhang, X. Liu, B. Qian, Y. Zhang, and F. Wu, “Cross-modality transformer for visible-infrared person re-identification,” in Proc. 17th Eur. Conf. Comput. Vis., 2022, pp. 480–496.
J. Zhao, H. Wang, Y. Zhou, R. Yao, S. Chen, and A. El Saddik, “Spatial-channel enhanced transformer for visible-infrared person reidentification,” IEEE Trans. Multimedia, vol. 25, pp. 3668–3680, 2023.
细化任务
基于图像/视频再识别
基于文本/图像再识别:注意力机制
行人换衣再识别:关键在于学习与服装无关的特征,如人体姿态、步态等
车辆再识别
跨模态再识别(红外-可见光....):基于CNN网络的单流、双流或其他结构、通过GAN实现风格转换....
无人机视角再识别
无监督再识别等...:利用CNN提取的特征进行聚类,生成伪标签;或者改进聚类算法和训练策略。
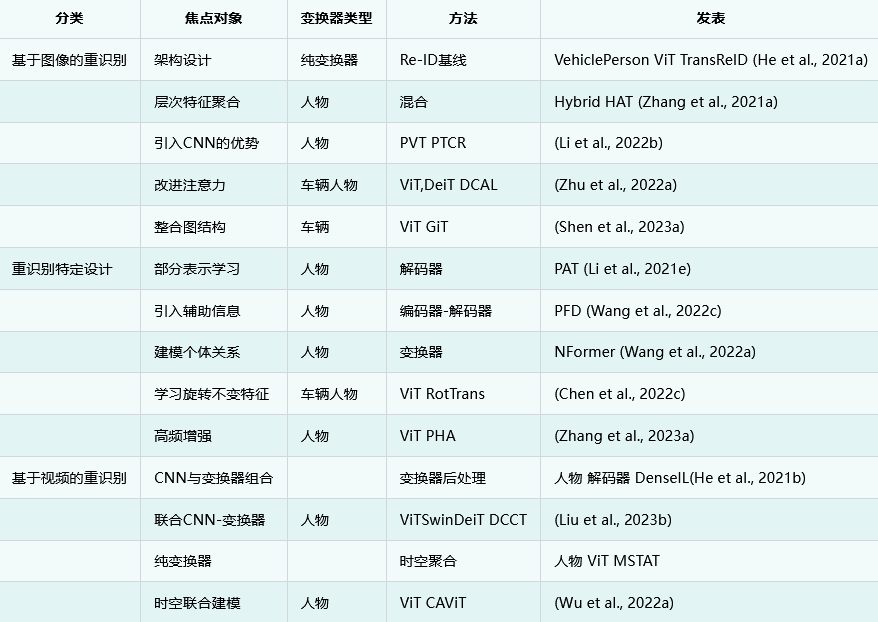
Transformer在ReID中的发展
TransReID (He 等,2021a)是第一个在 Re-ID 领域引入视觉变换器的方法,它在架构层面保留了变换器的两个优点。与 CNN 相比,Transformer 中的多头自关注方案能捕捉远距离的依赖关系,从而更好地关注不同的物体/身体部分。此外,Transformer 还能保留更详细的信息,而无需向下采样运算符,它以类似于 ViT(Dosovitskiy 等人,2020 年)的方式,为基于监督图像的单模态物体再识别建立了一个纯 Transformer 基线。即使简单地用视觉变换器替换基本 Re-ID 方法中的特征提取网络,在多个车辆和人物 Re-ID 数据集上的性能也能与最先进的方法相媲美,这反映了变换器在 Re-ID 任务中的强大潜力。
受此启发,一些后续方法设计了特殊的变换器架构,如金字塔结构(李等人,2022b)、分层聚合(张等人,2021a;谭等人,2023)、图结构(沈等人,2023a)等,而另一些方法则有意改进注意力机制(陈等人,2021b;朱等人,2022a;田等人,2022;沈等人,2023b)。考虑到 CNN 和变换器的相互配合,Li 等人(Li et al., 2022b)开发了一种类似 CNN 的金字塔变换器结构来学习多尺度特征并改进补丁嵌入过程,利用与抗锯齿块的卷积来捕捉平移不变信息。同样,基于 CNN 提取的分层特征,HAT(Zhang 等人,2021a)被提出来,借助变换器将不同尺度的特征聚合在一个全局视图中。GiT(Shen 等人,2023a)在变换器中引入了图,以挖掘补丁内节点的关系。
为了改进 Transformer 中的注意方案,Zhu 等人(Zhu et al.,2022a)提出了一种双重交叉注意学习策略,强调全局图像与局部高响应区域之间的相互作用以及图像对之间的相互作用。考虑到同一身份的不同外观的影响,Shen 等人(Shen 等,2023b)在 Transformer 编码器中引入了交叉注意,以合并来自不同实例的信息。从提高 ReID 中 Transformer 效率的角度出发,Tian 等人(Tian et al.对于轻量级 Re-ID 模型,Mao 等人(Mao et al.它以硬件友好的方式去除多余的标记和头,在不牺牲 Re-ID 精确度的前提下实现了降低推理复杂度和模型大小的目标。
图A:基于VID的ReID baseline
图B:用于学习多尺度特征的金字塔Transformer
图C:用于聚合分层特征的Transformer和CNN混合架构
图D:图结构与Transformer的结合

特定于 Re-ID 的设计。针对不同的对象和 Re-ID 的特定挑战,许多研究都在探索如何应用 Transformer 进行 Re-ID 的特定调整(Zhu 等人,2021b;Lai 等人,2021;Li 等人,2021e)。对于 Re-ID 最关键的局部判别信息挖掘,Vision Transformer 天然具有注意力和斑块嵌入,可轻松用于捕捉局部判别信息以增强表示。而在 CNN 中加入注意力机制以关注更多判别信息是以往研究的主流做法。许多利用Transformer 的特殊属性来学习局部特征的新思路也在不断涌现并迅速发展。
TransReID(He等人,2021a)在Transformer baseline上设计了移位和补丁洗牌操作来学习局部特征,这有利于增强干扰不变性和鲁棒性。Zhu 等人开发了一种自动对齐变换器(AAformer)(Zhu 等人,2021b),用于自适应定位人体部位。它通过向变换器引入可学习的部件标记来学习局部表征,并将部件对齐整合到自我注意中。Zhang 等人的研究发现,自我注意会不可避免地稀释图像的高频成分。为了增强对重新识别非常重要的高频成分的特征表示,他们建议使用离散哈小波变换(DHWT)(Mallat,1989)来分割高频成分的斑块作为辅助信息(Zhang 等人,2023a)。对于车辆再识别,姿态和视角变化造成的特征不对齐是一个关键挑战。以前的方法是根据车辆部件的附加注释对齐特征来解决这一问题。为了使特征分解更加灵活和非结构化,(Qian 等人,2022 年)利用Transformer在空间维度上对车辆特征进行解耦,从而在全局范围内实现精细化特征学习。此外,Transformers在建立与 Re-ID 相关的语义知识和视觉特征之间的交互方面也非常有效。MsKAT(Li 等人,2022a)引入了状态消除Transformer来消除摄像头和视点的干扰,还引入了属性聚合Transformer来收集车辆属性信息,如颜色和类型。
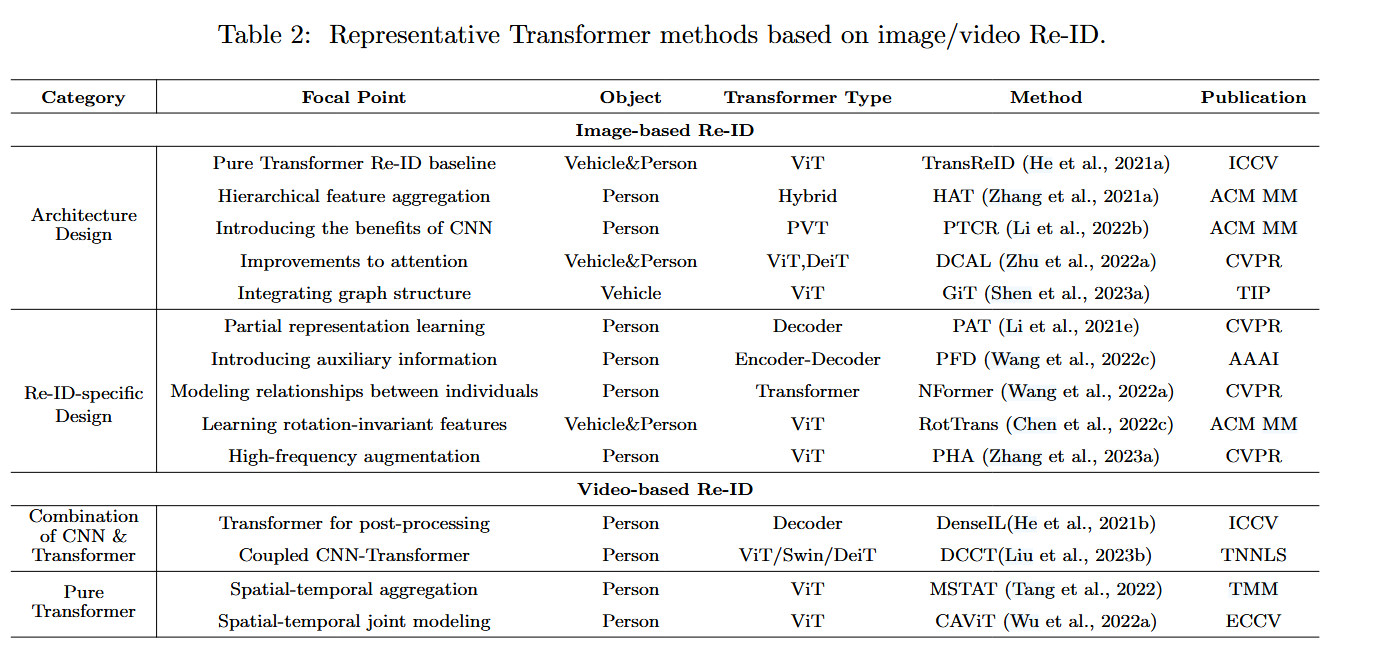
基于Transformer的视频重识别
视频再识别旨在充分利用帧序列的时间和空间交互作用来提取更具区分性的表征(Wu 等,2022a)。与需要额外模型来编码时间信息的基于 CNN 的方法相比,Transformer 被认为是处理序列数据的强大架构,具有先天优势。Transformer 中的全局关注机制可轻松适用于视频数据,以捕捉时空依赖性(Tang 等人,2022 年)。一组基于 Transformer 的视频再识别方法是混合架构(Liu 等人,2021a;Zhang 等人,2021c;He 等人,2021b)。它们通常是指先处理从其他模型(如卷积神经网络)中提取的特征,然后再使用 Transformer 模型进行进一步处理。Transformer 的主要用途在于其自我关注机制,该机制可捕捉序列中的长期依赖关系和上下文信息。张等人(Zhang et al.,2021c)为从 CNN 特征图转换而来的补丁标记设计了一个两阶段时空变换器模块,其中空间变换器侧重于不同背景的对象区域,而随后的时间变换器则侧重于视频序列,以排除噪声帧。同样基于 CNN 提取的特征,Liu 等人(Liu et al.,2021a)提出了一种多流变换器架构,通过空间变换器、时间变换器和时空变换器从三个角度强调视频特征。设计了一种基于交叉注意力的策略来融合多视角线索,从而获得增强的特征。此外,一些研究还考虑了 CNN 和 Transformer 在空间和时间上的互补学习。具体来说,DCCT(Liu 等人,2023b)为两个独立网络提取的特征引入了自注意和交叉注意,以建立空间互补关系,并设计了基于时间 Transformer 的分层聚合,以整合两个时间特征。DenseIL (He 等人,2021b)是一种由 CNN 编码器和 Transformer 解码器组成的混合架构,具有密集交互的特点。
基于Transformer的无监督重识别
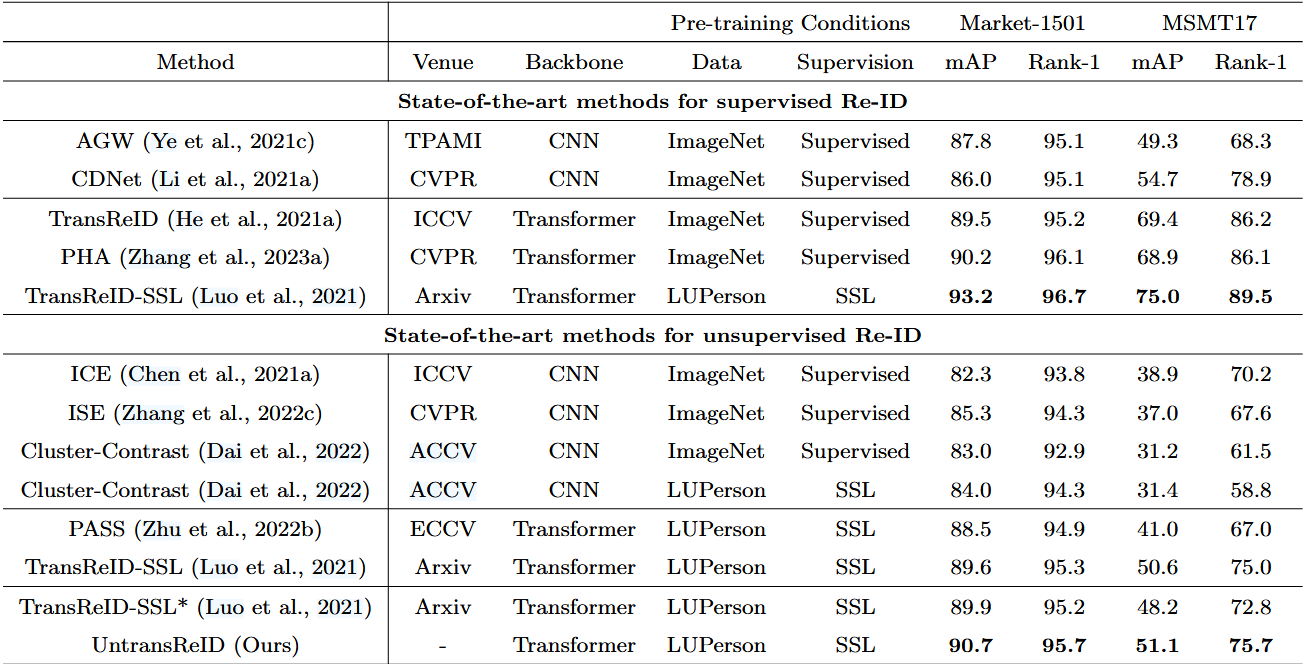
基于 CNN 和 Transformer 的最先进的有监督和无监督方法在两个广泛使用的数据集 Market-1501 和 MSMT17 上的比较。
Vision Transformer 在无监督学习方面的优势体现在以下几个方面:
1) Transformer 模型对于大规模无标记数据具有很强的可扩展性。自监督学习可以充分利用 Transformer 架构模型的表示能力(Caron 等人,2021 年)。
2) Transformer 结构的灵活性提供了更多样化的自监督范式,这对于 CNN 来说是极具挑战性的(He 等人,2022 年)。
LUPerson是一个专门用于人物再识别的大规模无标记数据集,随着LUPerson的出现,Luo等人(Luo等人,2021年)开始初步探索用于再识别的有效变换器自监督预训练范式,并取得了显著成果。他们首先在 ImageNet 和 LUPerson 预训练数据集上使用不同的自监督学习(SSL)方法进行了大量实验,研究了 CNN 和变换器的性能。此外,他们还设计了基于 IBN 的卷积干,以取代 ViT 中的标准 patchify 干,增强局部特征学习,从而提高了 Transformer 的稳定性和域不变性。结论是,Transformer 在预训练方面领先于 CNN。值得注意的是,在使用 DINO(Caron 等人,2021 年)对 LUPerson 上的 Transformer 进行预训练,并使用常见的无监督 Re-ID 方法(Dai 等人,2022 年)进行微调的完全无监督条件下,Re-ID 的性能甚至可以与最先进的有监督 Re-ID 方法相媲美。这可以说是无监督 Re-ID 领域的一个重大突破。在此基础上,后来的 PASS(Zhu 等人,2022b)在自监督Transformer预训练中进一步集成了 Re-ID 特有的部件感知特性。受 DINO(Caron 等人,2021 年)的启发,PASS 引入了几个可学习的标记来提取部分级特征,进一步加强了 Re-ID 的细粒度学习。具体来说,它将图像划分为几个固定重叠的局部区域,并从中随机裁剪局部视图,而全局视图则从整个图像中随机裁剪。在知识提炼过程中,所有视图都通过学生,只有全局视图通过教师。
此外,研究人员还尝试研究Transformer在 Re-ID 中的泛化能力。Ni等人(Ni et al.,2023)采用不同的Transformer和CNN作为骨干,评估了从Market(Zheng等人,2015)到MSMT(Wei等人,2018)的跨域性能。结果表明,Vision Transformers 的性能明显优于 CNN。
基于Transformer的跨模态重识别
在跨模态重识别中,Transformer的主要优势在于其输入可包括多个标记序列,每个序列都具有不同的属性,从而通过注意力机制促进不同模式的关联,而无需对架构进行任何更改。
可见光-红外再识别
可见光-红外再识别的主要挑战在于两类图像之间的模态差距。Transforme的应用为可见红外再识别问题带来了许多好处。例如,Transforme倾向于学习形状和结构信息,而 CNN 则依赖于局部纹理信息(Naseer 等人,2021 年)。由于红外图像缺乏色彩和光照条件,Vision Transformer能更好地捕捉模态不变信息,并具有更强的鲁棒性。另一方面,Vision Transformer的结构和注意力能使局部跨模态关联在补丁标记级别轻松建立,这对于再识别的细粒度属性至关重要,尤其是在模态差距较大的情况下。
现有可见光-红外再识别的主流方法是学习模态共享特征,将特征解耦为特定模态特征和共享模态特征,然后在特征水平上进行模态对齐。Jiang 等人(Jiang et al., 2022)开始尝试采用 Transformer 的编码器-解码器架构进行模态特征增强和补偿,以促进 RGB 和红外模态更好地对齐。他们分别为 RGB 和红外模态构建了两套可学习的原型,以表示全局模态信息。在变换器解码器中,红外原型被视为对 RGB 模态的查询,RGB 样本标记级的部分特征被用作键和值。通过部分特征与模态原型之间的交叉注意对应关系,对部分特征进行聚合,从而得到补偿的红外模态特征。相比之下,Liang 等人(Liang et al., 2023)在 Transformer 中引入了可学习嵌入,以类似于位置编码的方式挖掘特定模态特征,并采用模态移除过程来减去学习到的特定模态特征。
文本-图像再识别
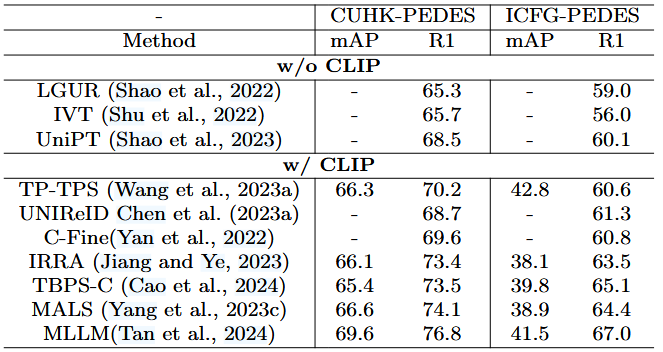
文本-图像再识别是指一种跨模态检索任务,其目的是根据给定的描述目标外观的文本查询,从图像库中识别目标对象(人或车)。再识别中的 CLIP。作为 Transformer 在多模态应用领域的里程碑式成果,对比语言-图像预训练(CLIP)(Radford 等人,2021 年)的提出开创了文本-图像通信大规模预训练的新纪元。CLIP 利用文本信息来监督视觉任务的自我训练,从而将分类任务转化为图像任务。
在训练过程中,包括图像编码器和文本编码器在内的双流网络分别处理文本和图像数据,并利用对比学习来学习文本图像对之间的匹配关系。预先训练好的模型不需要任何训练数据就能直接执行零镜头图像分类,达到了与监督分类相当的准确率。近来,CILP 已成为下游文本图像再识别任务的有力工具。一些 Re-ID 作品直接引入 CLIP 作为具有良好泛化能力的预训练模型(Han 等,2021 年),或进一步扩展跨模态关联挖掘的设计(Jiang 和 Ye,2023 年;Yan 等,2022 年;Zuo 等,2023 年),还有一些作品更加注重利用 CLIP 中与 Re-ID 相关的文本信息来更好地辅助下游 Re-ID 任务(Li 等,2023a 年;Wang 等,2023a 年)。
考虑到直接微调 CLIP 的有效性,Yan 等人(Yan et al.在预训练 CLIP 的基础上,他们进一步捕捉图像片段与单词之间的关系,从而建立精细的跨模态关联。在 CLIP 的启发下,Zuo 等人(Zuo et al.,2023)提出了更适合人物对象的语言图像预训练框架 PLIP。为了明确建立细粒度的跨模态关系,他们提出了一个用时尚生成的文本描述构建的大规模人物数据集,并引入了三个前置任务。第一项任务是语义融合图像着色,即根据文本描述恢复灰度人物图像的颜色信息。第二项是视觉融合属性预测,通过配对图像预测文本描述中被掩盖的属性短语。最后是视觉语言匹配。而 IRRA(蒋和叶,2023 年)则以 CLIP 为初始化模型,设计了一个跨模态隐式关系推理模块,通过自注意和交叉注意机制有效地构建视觉和文本表征之间的关系。这种融合表征用于执行掩码语言建模(MLM)任务,无需任何额外的监督和推理成本,实现了有效的跨模态关系学习的目的。He等人(He et al., 2023b)开发了一个CLIP驱动的框架,重点关注细粒度的跨模态特征配准。他们提出了 "视觉引导语义分组网络"(VisionGuided Semantic Grouping Network),通过对文本特征进行语义分组并将其与视觉概念对齐,减轻了细粒度跨模态特征的不对齐问题。此外,Wang 等人(Wang et al., 2023a)旨在利用视觉语言预训练(VLP)模型的双重泛化能力来增强基于文本的人物搜索。论文的重点是充分挖掘文本表征的潜力,利用文本中预训练的可迁移知识,并提出了两种针对描述性语料库的策略。与之前利用单模态预训练外部知识、缺乏多模态对应信息的方法相比,这些基于 CLIP 的文本图像再识别方法取得了显著的性能提升。
基于Transformer的特殊重识别
遮挡再识别
遮挡再识别是物体再识别的一种变体,用于应对图像中部分遮挡的挑战。在遮挡再识别中,人或物体的一部分被障碍物(如其他人、物体或结构)遮挡,使得模型难以提取完整的身份信息。最近,基于Transformer的方法为解决 Re-ID 的遮挡难题做出了巨大贡献(Wang 等,2023b;Mao 等,2023;Zhou 等,2022b;Cheng 等,2022b)。提取部分区域表示特征也是解决 Re-ID 中物体遮挡难题的一个好办法。部分感知Transformer(PAT)(Li 等人,2021e)的提出是为了利用Transformer编码器-解码器架构来捕捉不同的辨别身体部位,其中编码器用于获取像素上下文感知特征图,解码器用于生成部分感知掩码。为了解决错位和遮挡问题,Heet al.(He 等人,2023a)建议使用 CLIP(Radford 等人,2021 年)来捕捉辨别性和不变性区域特征。设计了一个区域生成模块,用于自动搜索和定位更具区分性的区域。对于广泛研究的人物对象,由于遮挡噪声或遮挡区域与目标相似,直观的解决方案是引导借助人体姿势信息进行局部特征学习。Wang 等人(Wang et al.,2022c)也采用了Transformer编码器-解码器结构,提出了一种姿势引导的特征分解方法。利用姿势估计器捕捉到的关键点信息,将一组可学习的语义视图引入解码器,从而隐式地增强解离出的身体部位特征。同样,在运动信息的辅助下,Zhou 等人(Zhou et al.,2022b)利用关键点检测和部件分割进行Transformer编码器-解码器建模。此外,一些Transformer研究还从其他角度分析了遮挡问题(Xu 等人,2022;Cheng 等人,2022b)。徐等人(Xu et al., 2022)设计了一种特征恢复Transformer(FRT),利用附近的目标信息来恢复闭塞特征。考虑到 k 个近邻中每个语义特征的本地信息与查询之间的相似性,FRT 过滤掉噪声,从而恢复被忽略的查询特征。程等人(Cheng et al.,2022b)利用从不同源数据集中学到的知识生成可靠的语义线索,以缓解现成语义模型与 Re-ID 数据之间的领域差异。Transformer 允许将人类解析结果作为可学习标记嵌入输入中,并采用加权求和操作来整合来自多个来源的解析信息。此外,由于 Transformers 中的自我关注主要强调低层次的特征相关性,因此从本质上限制了不同身体部位或区域之间的高阶关系,而这些关系对于被遮挡人员的再识别尤为重要。为了解决这个问题,Li 等人(Li et al., 2024b)引入了二阶注意力模块,利用频谱聚类技术从注意力权重中提取上下文信息。
换衣重识别
换衣再识别是人特有的挑战,是一个困难但更实际的问题(Liu 等,2023a)。在这种情况下,以服装视觉外观为主的判别特征表征将失效。现有研究已经开始对Transformer的应用进行初步调查,以应对这一更为复杂的挑战。李等人(Lee et al., 2022 年)评估了换衣 ReID 场景中的不同骨干,与 CNN 相比,Transformer表现出了显著的性能优势。在此基础上,为了进一步消除服装或配饰相关特征的影响,设计了一个属性去偏差模块。其核心思想是将生成的人物实例属性标签作为辅助信息,并采用基于对抗学习的梯度反转机制来学习属性无关表征。
无人机中的重识别
无人机中的物体再识别包括在动态鸟瞰拍摄的大量航空图像中识别特定物体(Organisciak 等人,2021 年)。它在不同场景中也有广阔的应用前景。利用无人机捕捉的航空图像进行再识别是一种尚未充分开发的应用场景。与广泛使用的固定相机不同,无人机拍摄的图像具有更高的分辨率和更强的识别能力。
Chen 等人(Chen et al., 2022c)分析了鸟瞰图中的车辆和人员,认为 Re-ID 在无人机场景中面临两个关键挑战:尺寸差异明显的边界框和旋转方向不确定的物体。得益于 Vision Transformer 中图像补丁和标记级特征之间的对应关系,这项工作的洞察力在于对最初学习到的补丁特征进行模拟旋转操作,以生成增强的多样性旋转特征。另一项研究(Ferdous 等人,2022 年)探讨了如何增强金字塔Vision Transformer,利用多尺度特征在无人机场景中进行物体再识别。除了全无人机视角 Re-ID 外,一些研究还关注空中和地面视角之间的跨视角匹配问题。(Zhang等人,2024)提出了一种视图解耦Transformer,专门解决显著的视图差异问题,旨在解耦与视图相关和与视图无关的组件。
未来展望
重新识别与大型语言模型的结合
将大型语言模型(LLM)整合到 Re-ID 任务中已成为一种大有可为的趋势。在这种情况下,Re-ID 将受益于 LLM 在生成或处理补充图像数据的文本描述方面的先进能力。事实上,一些初步研究已经探索了这一方向:
(1) 文本辅助。通过生成或理解视觉数据的文本描述,LLMs 可提供更详细的上下文信息,从而提高基于图像的再识别性能(Li 等人,2023a;Yang 等人,2024)。
(2) 跨模态图像-文本再识别。LLMs 可利用其在视觉和文本模式上的双重优势,将视觉特征与自然语言描述相统一,从而创建更强大的表征,提高识别能力(Jiang 和 Ye,2023;He 等人,2023b)。
(3) 无标记数据的利用。LLM 可以为大型数据集中的图像自动生成标题或标签,从而减少人工标注的需要,并增加数据集的规模,以便更有效地进行 Re-ID 模型训练(Tan 等人,2024;Zuo 等人,2024)。
(4) 语义理解。LLM 可增强对图像区域的细粒度语义理解,尤其是在遮挡或低质量数据等具有挑战性的情况下。
(5) 模型泛化。LLM 具备强大的泛化能力,能够更有效地处理未见类别,进一步提高 Re-ID 系统的鲁棒性(Tan 等人,2024 年)。
展望未来,LLM 在各种 Re-ID 应用场景中具有更大的潜力,为进一步提高 Re-ID 系统在不同应用中的适应性、准确性和可扩展性提供了机会。
统一的大规模再识别基础模型
要满足 Re-ID 的实际应用需求,主要需要利用统一的大规模模型,以适应多模态和多对象场景。在跨模态 Re-ID 中,现有的研究往往只集中在两种特定的模态上。然而,查询线索的来源是多种多样的,因此探索如何整合来自不同感官或数据源的信息以创建一个真正与模式无关的通用 Re-ID 模型意义重大。Transformer 可灵活处理多模态输入,具有强大的关系建模能力和处理大规模数据的可扩展性,因此在这一问题上显示出巨大的潜力。最新研究表明,Transformer 在构建多模态大型模型方面不断取得突破。例如,Meta-Transformer(Zhang 等人,2023b)可理解 12 种模态信息,并提供无边界多模态融合范例。在再识别领域,也有一些关于多模态统一模型的初步探索(Li 等,2024a;He 等,2024)。此外,统一与 Re-ID 相关的各种目标相同的任务也是一个具有现实意义的发展方向。在我们的调查中,可以看到最近的一些研究通过利用 Transformer 模型来统一以人类为中心的各种视觉任务取得了突破性进展(Tang 等,2023;Ci 等,2023;Chen 等,2023b)。此外,为 Re-ID 中的多个对象构建通用模型也是一项重大挑战。这意味着许多依赖特定信息的方法面临困难。特别是在动物再识别领域,建立多物种稳健模型对实际应用具有重要意义。
为重识别(Re-ID)高效部署Transformer
我们的调查表明,Transformer在重识别领域确实表现出了强大的性能。然而,由于自我关注计算需要大量的计算支持,相关的资源消耗相对较高。在视频监控和智能安防等实际应用中,对 Re-ID 模型的实时性能和轻量级部署的要求越来越高(Mao 等,2023 年)。如何在保持Transformer在再识别中的稳健性能与降低计算复杂度之间取得平衡,成为未来研究的重要方向。此外,在一般领域已经开发出了许多预训练的大规模通用基础,如何将这些通用知识有效地转移到特定的再识别任务中也值得研究(丁等人,2023 年)。考虑到大规模动态更新摄像机网络中的灾难性遗忘问题,如何根据下游场景对先前学习的再识别模型进行有效微调是另一个重要的探索方向(Pu 等,2023;Gu 等,2023)。
评论区